
Imagine your application needs data – users, orders, products. That data might live in a PostgreSQL database, a MongoDB collection, an API, or even a CSV file. The Repository Pattern is a way to hide all of that complexity behind a simple, clean interface.
Your business logic never says “run this SQL query” or “call this API endpoint”. It just says “give me the user with ID 5” – and the repository figures out how to do that.
The Core Idea
Think of a repository like a librarian:
- You don't care how books are stores (shelves, alphabetically, by ISBN)
- You just say “give me this book” or “add this book”
- The librarian handles all the details
In code, your app says userRepository.findById(5) and doesn't care if that hits a DB, cache, or API.
Definition
The Repository Design Pattern is a structural pattern that mediates data access by providing an abstraction over the data layer. It allows you to decouple the data access logic and business logic by encapsulating the data access logic in a separate repository class.
What Problem Does the Repository Pattern Solve?
At its core, the Repository Pattern solves this problem:
“How do we keep business logic independent from how data is stored or retrieved?”
Without it, your system often ends up like this:
Business Logic → SQL Queries / API Calls → DatabaseThis creates:
- Tight coupling
- Hard-to-test logic
- Fragile systems when storage changes
The repository pattern introduces a middle layer that abstracts data access.
Why is it important?
Because data access changes frequently, but business rules should not.
Examples:
- Switching databases (SQL -> NoSQL)
- Moving to microservices
- Adding caching
- Changing APIs
Without abstraction, every change breaks business logic.
Relation to Separation of Concerns & Clean Architecture
The Repository Pattern enforces:
Separation of Concerns
- Business logic -> What to do
- Repository -> How to fetch/store data
Clean Architecture Alignment
[ Domain / Business Layer ]
↓
[ Repository Interface ]
↓
[ Infrastructure (DB, API, Cache) ]Business logic depends on abstractions, not implementations.
Core Components
1 Entity
Represents core business object
Example:
- User
- Order
- Product
Contains business rules, not database logic
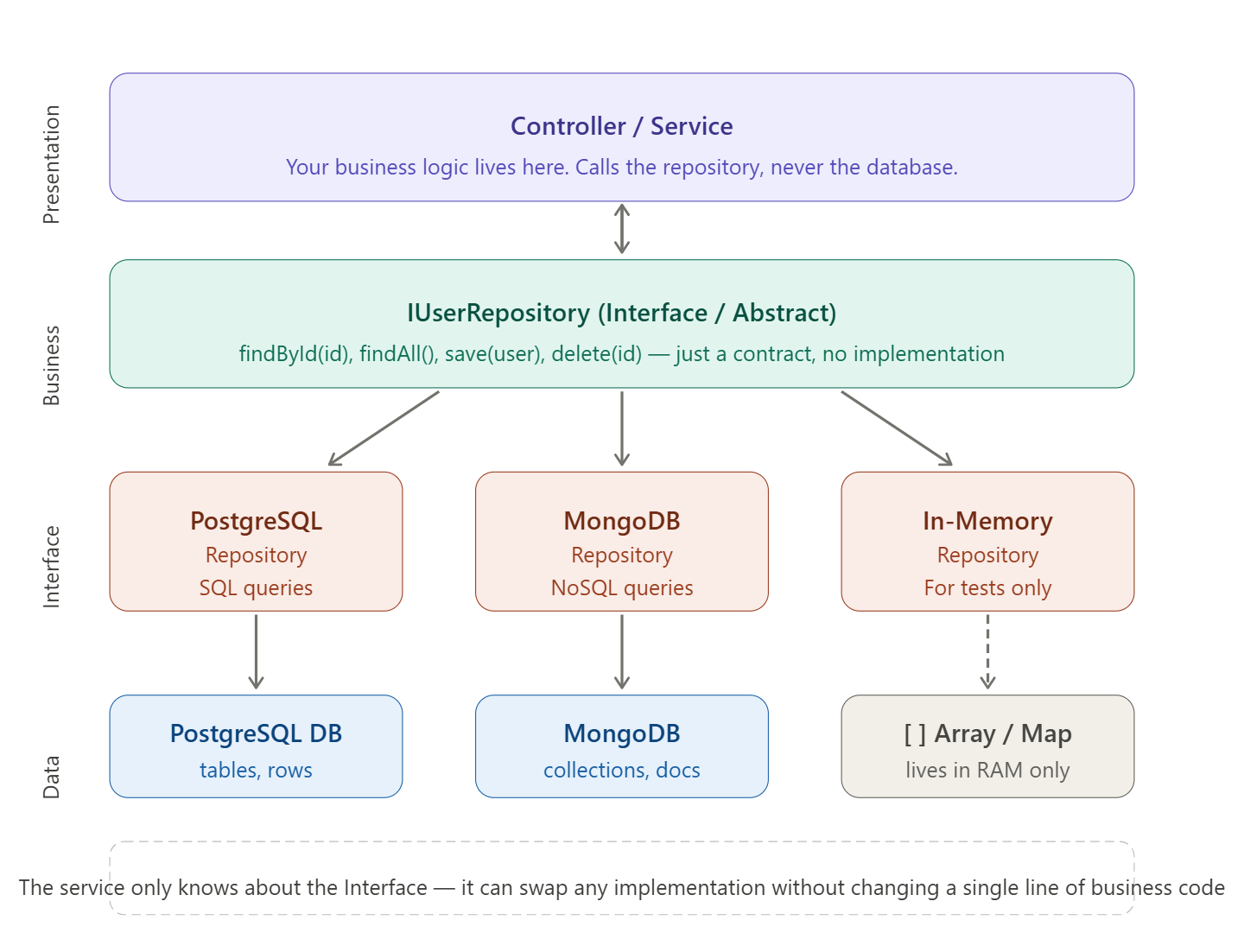
2 Repository (Interface / Abstraction)
Defines what operations are allowed
Does NOT define how they work
Examples:
- GetById
- Save
- Delete
- FindByCriteria
3 Data Source
Where data actually lives:
- Database
- API
- File system
- Cache
4 Repository Implementation
Implements repository interface
Talks to data source
Handles:
- Queries
- Mapping (data <-> entity)
Benefits and Trade-offs
Advantages
1 Decoupling
Business logic is independent of data storage
2 Testability
You can replace repository with a fake:
Fake Repository → returns predefined data3 Maintainability
All data logic is centralized.
4 Scalability
Easy to:
- Add caching
- Add replicas
- Optimize queries
Disadvantages
1 Over-engineering
For simple CRUD apps, it adds unnecessary complexity.
Introduce an additional overhead in smaller applications where a simple data access strategy could suffice.
2 Abstraction leakage
If poorly designed, DB details may leak into repository.
3 Too generic repositories
Losing domain meaning (bad design).
4 Complexity
Adds an extra layer of abstraction, which can increase the complexity of the codebase.
Real-World Analogy
Bank Teller Analogy
- You (business logic) -> want money
- Teller (repository) -> handles request
- Bank vault (data source) -> stores money
You never go into the vault yourself.
You say:
“Give me ₹10,000”
NOT:
“Open vault, go to shelf 3, take bundle 45…”
Implementation Blueprint (Language-Agnostic)
Interface Definition
INTERFACE Repository<Entity>:
METHOD findById(id)
METHOD findAll()
METHOD save(entity)
METHOD delete(entity)Concrete Implementation
CLASS DatabaseRepository IMPLEMENTS Repository:
METHOD findById(id):
data = query data source
RETURN mapToEntity(data)
METHOD save(entity):
data = mapToStorageFormat(entity)
persist to data sourceBusiness Logic Usage
CLASS BusinessService:
DEPENDS ON Repository
METHOD execute():
entity = repository.findById(id)
entity.applyBusinessRule()
repository.save(entity)

Leave a comment
Your email address will not be published. Required fields are marked *