
In this article we will assume we are the owner of an website which is deployed on a server. It currently has no end users. We will gradually scale it up to serve the millions of users.
Big picture: what “scale” means
Scaling = keeping the system usable as load (users, requests, data) grows.
That means:
- Performance (latency stays low)
- Throughput (system handles more requests/sec)
- Availability (uptime & resilience)
- Cost-efficiency (don't spend forever)
- Maintainability (you can change it safely)
We will manage these by making architecture choices and operational investments over time.
Single Server Setup
Initially everything runs on a single server. Journey of a thousand miles begins with a single step.

Let's understand the request flow in the single server setup:
As you can see from the diagram above:
- User enters the website name, such as the
www.example.com, The request goes to the Domain Name System (DNS) Server, which is a 3rd party server. It is known as the phonebook of the internet and has the mapping of thedomainnames and their corresponding serverIPaddress. - DNS Server returns the
IPaddress of the entereddomainname. For our case it return202.20.77. - Now we have the
IPaddress of the server. Then HTTP request are sent directly to the web server. - The web server handles the request and returns either HTML pages or JSON response.
Learn more about HTTP Request over here:
This is quite a simple architecture, it can't handle much of users as it has only one webserver and this webserver has its own database.
Limitations of a Single Server:
Single Point of Failure (SPOF):
- If the web server goes down, the entire application becomes unavailable.
- Performance bottleneck:
- All HTTP requests – API calls, static files, database queries – are handled by the same machine. As users increase, CPU, RAM, and I/O will quickly get overloaded.
- Limited Scalability:
- A single server can only scale vertically (by adding more RAM or CPU). But there's always a physical and cost limit.
- Tight Coupling with Database:
- The database resided on the same machine, which means both compete for the same system resources. We can't scale them individually.
Decouple the Database
The next step toward scaling is to separate the database from the web server.
As with the growth of the user base, one server is not enough, and we need multiple servers: one for the web/mobile traffic, the other for the database. Separating web/mobile traffic (web tier) and database (data tier) servers allows them to be scaled independently.

This separation allows each part to scale independently – for example, upgrading the database machine or replicating it without touching the web server.
Similarly we can scale the web server.
Which DB to Use
Databases come in many forms – each one optimized for a specific type of data model, query pattern, or scalability.
There's no “best” database – only the right one for the right use case.
1 Relational Database (RDBMS)
Data model:
Tables (rows and columns) with relationships (foreign keys).
Query language:
SQL (Structured Query Language)
Use When:
- Data is structured and has clear relationships.
- You need ACID guarantees – transactions that must be consistent and reliable.
- You perform complex queries and joins.
Pros:
- Strong consistency
- Mature ecosystem and tooling
- Ideal for financial, user, and transactional data
Cons:
- Not flexible for rapidly changing schemas
- Horizontal scaling (sharding) is complex
For most developers, relational databases are the best option because they have been around for over 40 years and historically, they have worked well.
2 NoSQL Database
The term NoSQL means “Not only SQL.”
They were built to overcome the limitations of relational databases – especially scalability and schema flexibility.
NoSQL isn't one single kind – it's a family of types
A. Document Databases
Examples: MongoDB, CouchDB, Firebase Firestone
Data model: JSON-like documents (nested key-value pairs)
Use When:
- Data is semi-structured or varies per record
- You want flexibility – no predefined schema
- Your app evolves rapidly (startups, dynamic content)
Pros:
- Schema-less
- Easy to scale horizontally
- Great for APIs that exchange JSON
Cons:
- Joins and transactions are limited or complex
Example:
{
"user_id": 123,
"name": "TheJat",
"skills": ["System Design", "C++", "AWS"]
}
B. Key-Value Stores
Example: Redis, DynamoDB, Riak
Data model: Simple key -> value pair
Use When:
- You need fast lookups by key (session data, caching)
- You can store the whole object as value (no complex queries)
Pros:
- Extremely fast (in-memory)
- Perfect for caching and session management
Cons:
- Limited query capability (no filtering, joins, or sorting)
Example:
| Key | Value |
|---|---|
session_1 | {user_id: 101, token: "abc123"} |
C. Column-Family Stores
Examples: Apache Cassandra, HBase, ScyllaDB
Data model: Columns grouped into families – like a hybrid of RDBMS and key-value stores.
Use When:
- You have large-scale, write-heavy workloads (analytics, logs).
- You need high availability and eventual consistency.
Pros:
- Scales horizontally across many nodes
- High write throughput
Cons:
- Complex data modeling
- Not ideal for ad-hoc queries
D. Graph Databases
Examples: Neo4j, Amazon Neptune, ArangeDB
Data model: Nodes (entities) and Edges (relationships)
Use When:
- You need to explore relationships between entities – social networks, recommendation engines, fraud detection.
Pros:
- Great for traversing relationships
- Natural fit for connected data
Cons:
- Not suitable for tabular or analytical workloads
Example:
(User)-[:FOLLOWS]->(User)
or
(Customer)-[:BUYS]->(Product)Scaling
Previously we separated the database from the web server.
This was a big improvement – the database and web server no longer compete for the same CPU and memory.
The database has its own dedicated machine, and the web server focuses purely on handling HTTP requests and business logic.
But even with this setup, you will quickly notice a problem as your user base grows.
As more and more users starts visiting the site, every single request still lands on one web server.
That one server is doing everything:
- Handling HTTP requests
- Running business logic
- Accessing the database
- Serving static files
- Managing concurrent connections
At first, this might be fine – say, for a few hundred or even a few thousand users.
But beyond that, the web server's CPU, RAM, and network bandwidth become overwhelmed.
Eventually:
- Requests start timing out
- Response time increases
- Server may crash under high load
In short:
We have removed one bottleneck (database), but now the web server itself becomes the next bottleneck.
How Do We Handle More Traffic?
We have two ways to make a server handle more users:
- Vertical Scaling (Scale Up)
- Adding more power to the same server (more CPU, RAM, SSD, etc.)
- Horizontal Scaling (Scale Out)
- Add more servers and distribute traffic among them.
Option 1: Vertical Scaling
At first, it seems simple – just upgrade the machine.
But vertical scaling has hard limits:
- Hardware can't be upgraded indefinitely. As there is limit of hardware.
- If that single machine fails -> your site goes down. (
Single Point of Failure)
So, while vertical scaling is useful in early stages, it's not sustainable for large-scale systems.
Option 2: Horizontal Scaling (The Real Solution)
Instead of one powerful server, we use multiple normal servers – each handling a portion of the incoming traffic.
This is called horizontal scaling, and it's the core idea behind every internet-scale architecture.

But now, we face a new question:
Which server IP address does the DNS resolver return?
and
How will users' requests know which web server to go to?
We can't ask the browser to pick randomly – we need something in front that manages this traffic distribution automatically.
The Solution: Load Balancer
A Load Balancer is like a smart “traffic manager” that sits in front of all your web servers.
It receives every incoming request and decides which server should handle it – based on current load, server health, or predefined algorithms.

How it Works:
- User makes a request (e.g.,
www.example.in). - DNS resolves it to the Load Balancer's IP.
- The Load Balancer receives the request.
- It forwards the requests to one of the available web (through private IP):
- Web Server 1
- Web Server 2
- That server processes the request, talks to the database if needed, and sends the response back through the
load balancer -> user.
Problem It Solves:
- No Single Point of Failure: If one server goes down, the load balancer routes traffic to healthy ones. Thus making high availability.
- Easier Scaling: If the website traffic grows rapidly, and two servers are not enough to handle the traffic, the load balancer can handle this situation. You only need to add more servers to the web server pool, and the load balancer automatically starts to send requests to them.
- Better Security:
Private IPsare used for communication between servers. A private IP is an address reachable only between servers on the same network; however, it is unreachable over the internet. The load balancer communicates with web servers through privateIPs.
Our Web server can now scale easily, but there is still bottleneck.
The data tier: The current design has one database, so it does not support failover and redundancy. It is single point of failure.
Database replication is a common technique to address those problems.
Database Replication
Our Previous design is already miles ahead of the single-server architecture. Our web tier can now scale horizontally – we can add as many web servers as needed to handle growing user traffic.
But soon, another bottleneck appears.
The New Bottleneck: The Database
Even though we have scaled out the web servers, every request still goes to one single database.
The database must handle:
- Read: fetching user data, articles, comments, etc.
- Writes: inserting new posts, likes, messages, etc.
Initially, it's fine – but as users grow into thousands or millions, the single database starts struggling with:
- Slow queries
- Increased latency
- Connection timeouts
- Disk I/O saturation
The Big Question: How to Scale the Database?
We can't just “add another database” without a strategy. Databases have relationships, indexes, and atomic transactions – so scaling them requires careful architecture design.
Master Slave Architecture
One of the simplest ways to scale a database is to replicate it.
We create:
- Once Primary (Master) database – handles all writes.
- One or more Read Replicas (Slaves) – handle read-only queries.

A master database generally only supports write operations. A slave database gets copies of the data from the master database and only supports read operations. All the data modifying commands like insert, update, delete must be sent to the master database. Most applications require a much higher ratio of reads to writes; thus, the number of slave databases in a system is usually larger than the number of master databases.
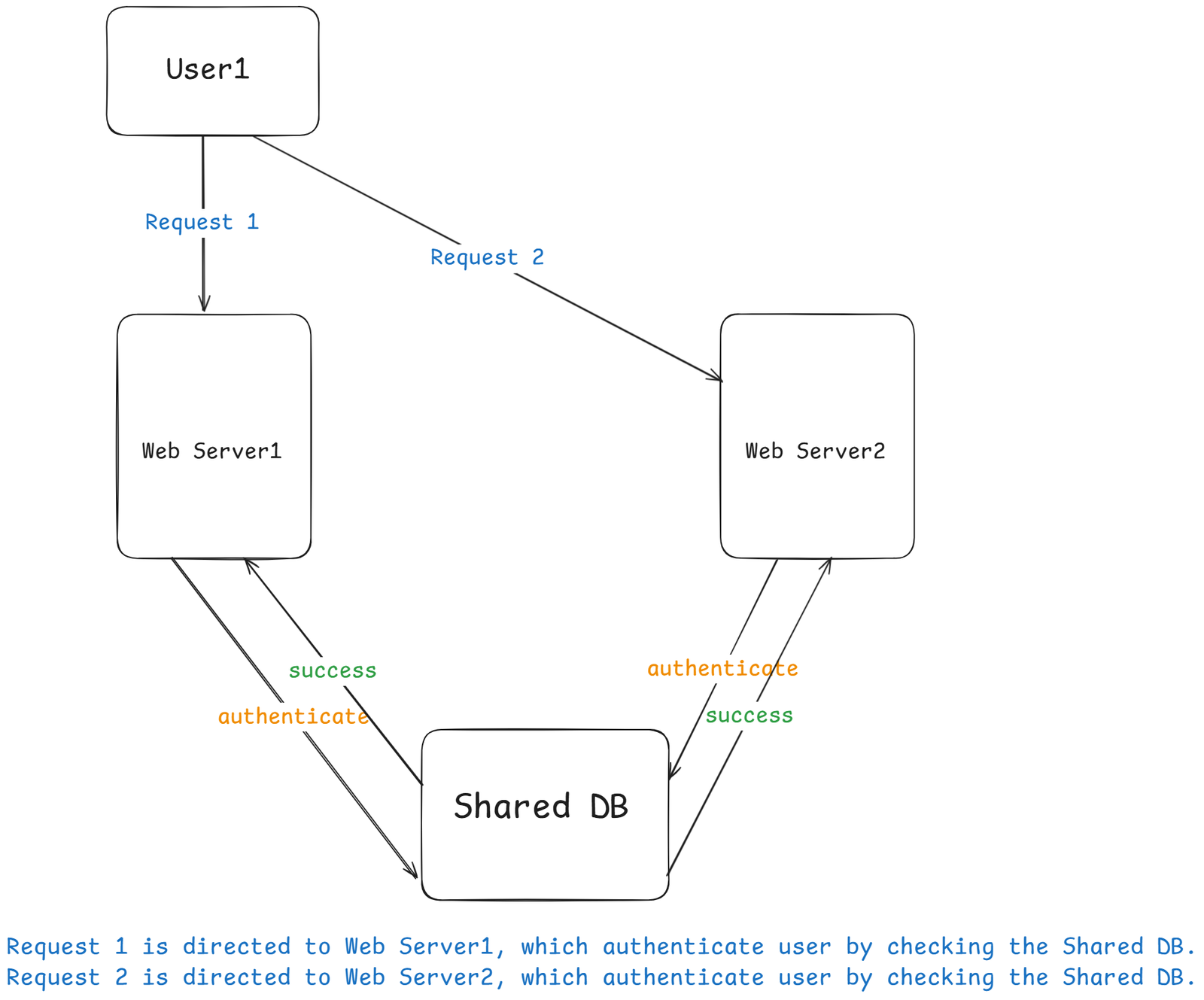
How It Works:
- Every write (
INSERT,UPDATE,DELETE) goes to thePrimary DB(Master DB). - These changes are asynchronously replicated to all Read Replicas.
- Web servers send read queries to replicas and write queries to the master.
Benefits:
- High Availability: By replicating data across different locations, your website remains in operation even if a database is offline as you can access data stored in another database server.
- Reliability: If one of your database servers is destroyed by any chance, then data is still preserved. You do not need to worry about data loss because data is replicated across multiple locations.
- Better Performance: In the master-slave model, all writes and updates happen in master nodes; whereas, read operations are distributed across slave nodes. This model improves performance because it allows more queries to be processed in parallel.
What if one of the database goes offline?
- If only one slave database is available and it goes offline, read operations will be directed to the master database temporarily. As soon as the issue is found, a new slave database will replace the old one. In case multiple slave database are available, read operations are redirected to other healthy slave databases. A new database server will replace the old one.
- If the master database goes offline, a slave database will be promoted to be the new master. All the database operations will be temporarily executed on the new master database. A new slave database will replace the old one for data replication immediately. In production systems, promoting a new master is more complicated as the data in a slave database might not be up to date. The missing data needs to be updated by running data recovery scripts. Although some other replication methos like multi-masters and circular replication could help, those setups are more complicated.
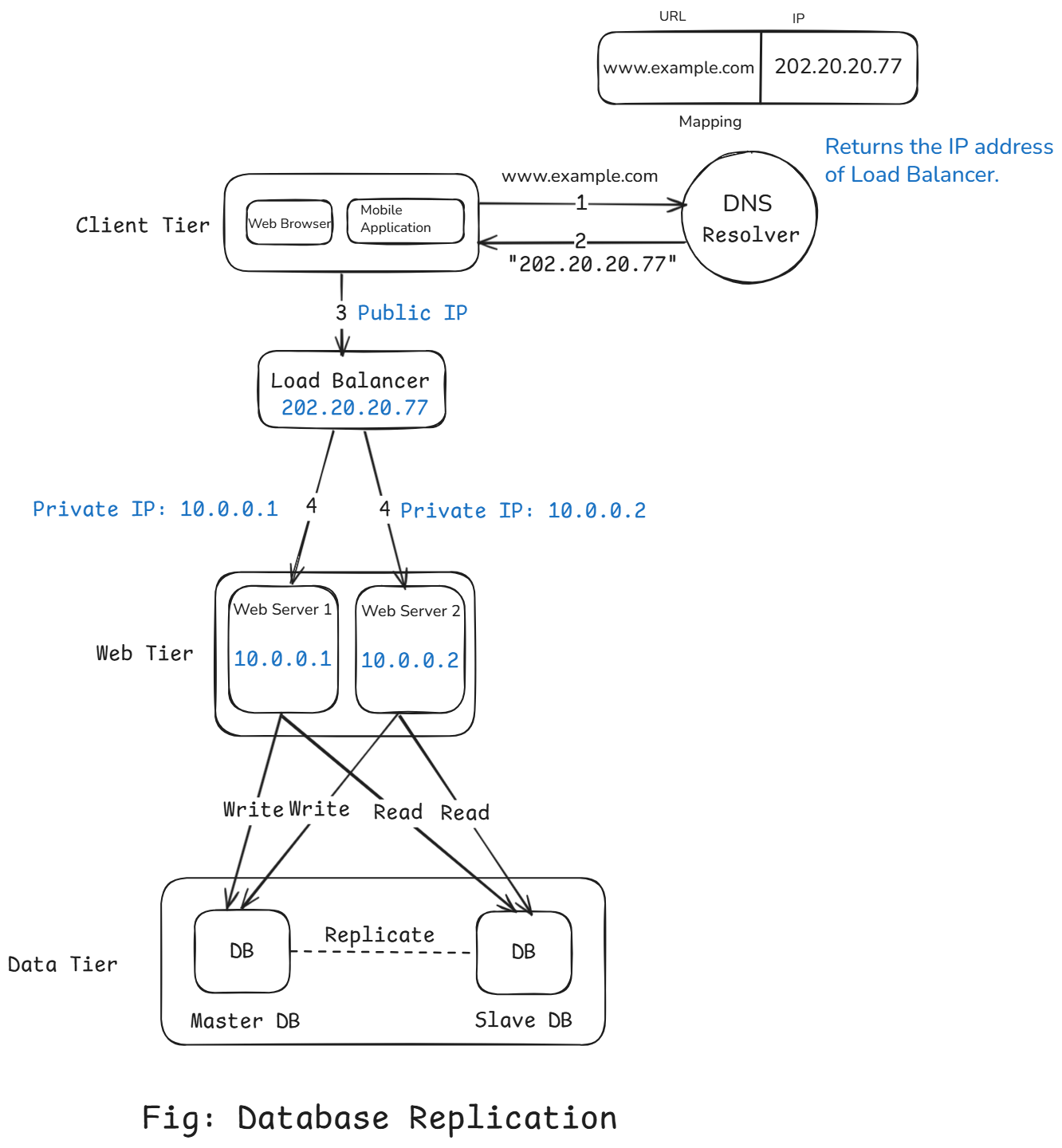
Working:
Let's us take a look at the design:
- A user gets the IP address of the load balancer from DNS.
- A user connects the load balancer with this IP address.
- The HTTP request is routed to either
Server 1orServer 2. - A web server reads user data from a slave database.
- A web server routes any data-modifying operations to the master database. This includes, insert, update, and delete operations.
Caching
It's time to improve the load/response time. This can be done by adding a cache layer and shifting static content (JavaScript/CSS/image/video files) to the content delivery network (CDN).
After replication still the database is handling a huge number of queries every second.
Even if those queries are simple, the database is a disk-based-system – it has to read data from disk, manage connections, locks, indexex, etc.
This adds latency and consumes resources.
That's where caching comes in.
The Core Idea: Don't Ask the Databases Every Time
When the same data is being requested again and again – like a user's profile, homepage feed, or trending articles – it makes no sense to keep hitting the database for each request.
Instead, we can store frequently accessed data in memory and return it instantly when needed.
This memory-based storage is called a cache.
What Is a Cache?
A cache is a high-speed data storage layer that stores a subset of data – typically temporary – so future requests for that data can be served faster.
It works on a simple principle:
“If you need it again soon, keep it nearby.”
Cache improves latency.

Working:
- Request comes in to the web server.
- Web server first checks the cache to see if the data exists (called a cache hit).
- If found -> returns data directly from cache (super fast).
- If not found (cache miss) -> queries the database, stores the result in cache for next time.
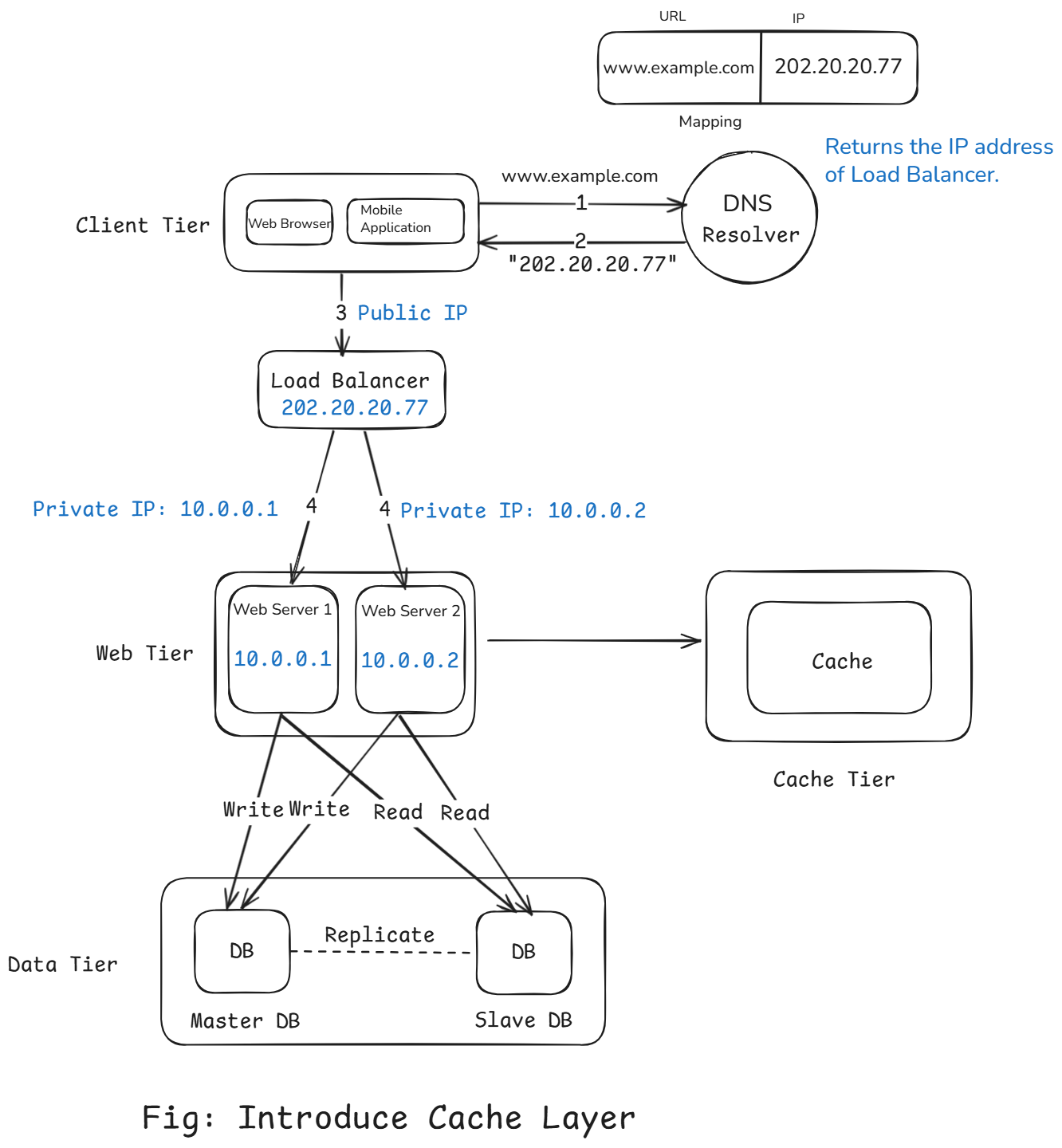
We have optimized the backend using load balancers, database scaling, and caching.
Now. it's time to reduce latency for global users with a CDN.
Content Delivery Network (CDN) – Serving User Globally
Even after adding caching and load balancing, our app might still feel slow for users in different regions.
Let's say your servers are hosted in Mumbai, and you suddenly get users from New York or London.
Those users will experience higher latency because their requests must travels thousands of kilometers to reach your origin server.
No matter how optimized your backend is –
physics still matters. The farther the user, the slower the request.
That's where CDNs (Content Delivery Networks) comes into play.
The Problem: Network Latency and Distance
When a user in New York requests an image hosted on a server in Mumbai:
- The request travels across continents.
- It passed through multiple network hops (routers, ISPs).
- Each hop adds latency (delay).
Even a few hundred milliseconds of delay can make your site feel sluggish.
Modern users expect websites to load within 2-3 seconds, especially on mobile.
So we need a way to bring content physically closer to users – no matter where they are.
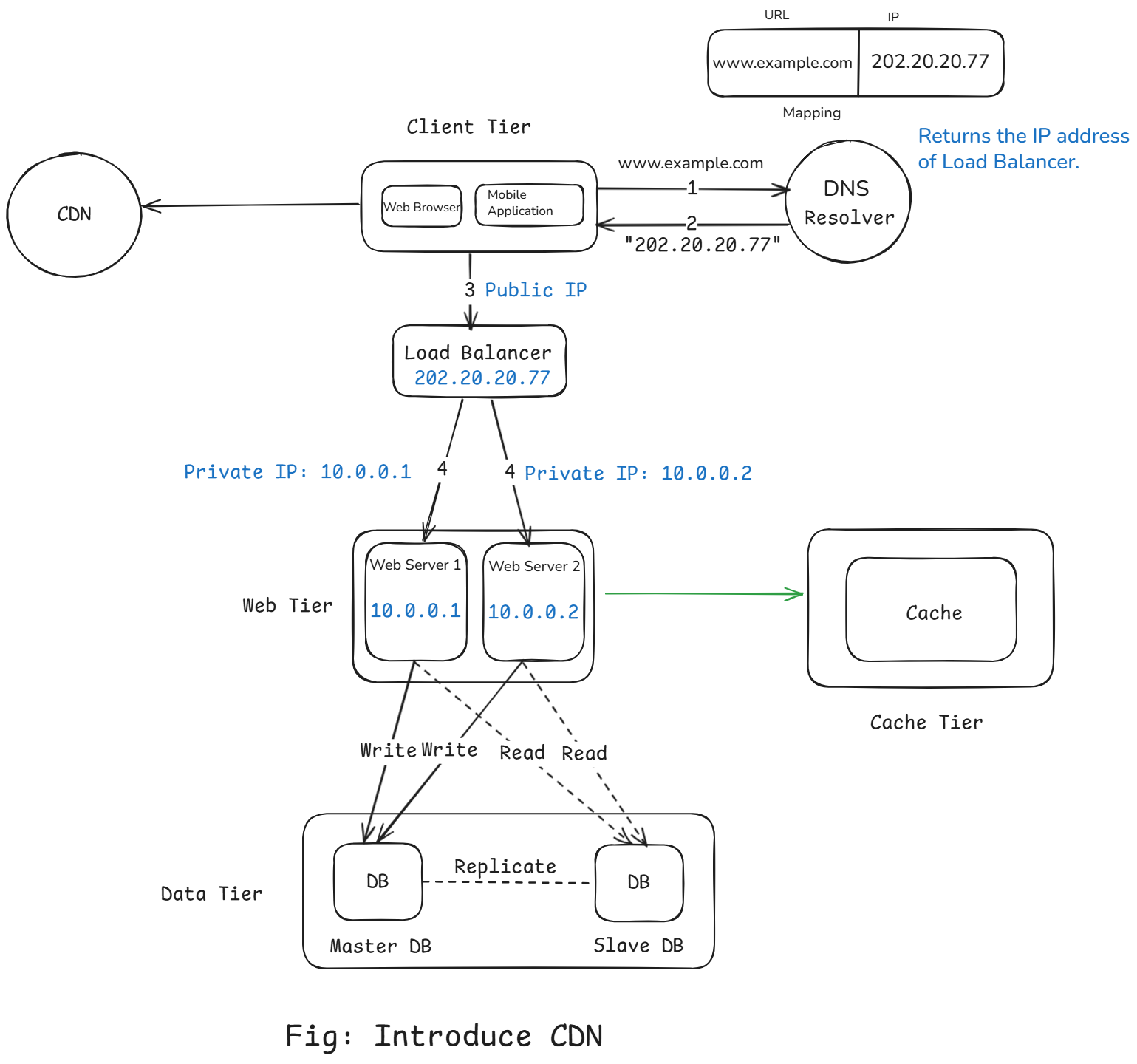
The Solution: Content Delivery Network (CDN)
A CDN is a globally distributed network of servers (called edge servers or PoPs – Points of Presence) that cache and serve your static content closer to users.
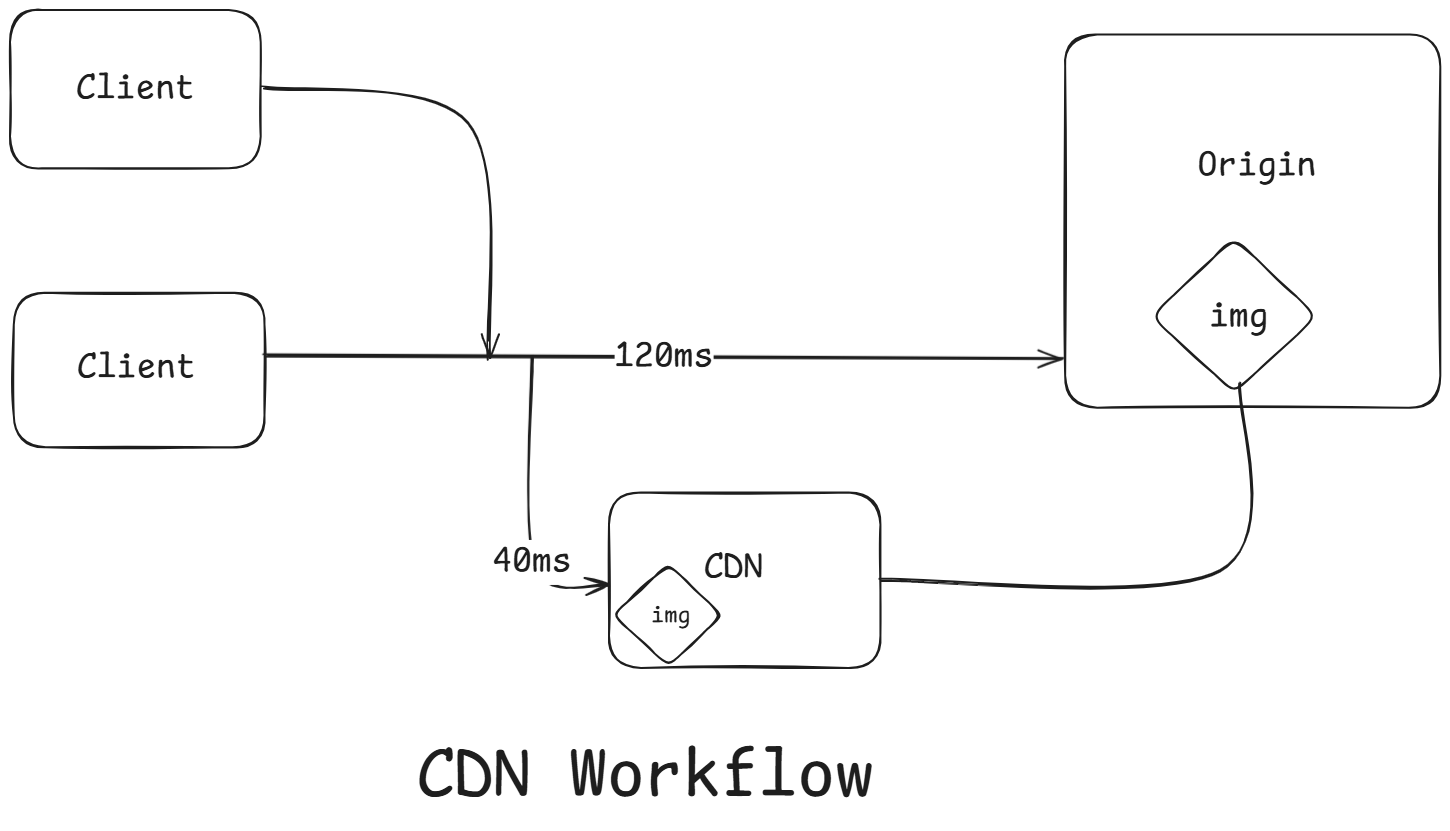
How a CDN Works?
- User requests a static asset (like an image, CSS, or JS file).
- The request goes to the nearest CDN edge server (based on location/DNS routing).
- If the content is cached there (cache hit), it's served instantly.
- If not (cache miss), the CDN fetches it from your origin server, stores a copy locally, and serves it to the user.
- Future users in that region get the same file directly from the CDN (no need to hit your main server again).
Auto Scaling
At this point, our system has two web servers: Web Server 1 and Web Server 2. However, these servers are not configured for auto scaling. This means that if the number of incoming requests increases, the system will continue to rely on these two servers.
As a result, the servers may become overloaded during periods of high traffic, leading to slower response times or potential service disruptions. Since auto scaling is not enabled, new servers will not be automatically added to handle the increased load.
Auto scaling is a cloud/infrastructure technique where the system automatically increases or decreases the number of servers based on demand. This helps maintain performance while minimizing cost. Such that when traffic is less then some server automatically shut down, while on heavy traffic they are turned back on.
In multi server architecture we hit a problem:
When users log in, how do we remember who they are across multiple servers?
The Problem: Stateless HTTP
The web runs on HTTP, and HTTP is stateless, every request is unique.
That means:
Each HTTP request is independent – the server doesn't remember anything about the previous request.
If a user logs in and sends another request:
- The new request doesn't “remember” the user.
- Without a mechanism to store identity, the user would have to log in again every time.
That's where sessions come in.
What Is a Session?
A session is a temporary, server-side record mechanism that stores information about a user across multiple requests.
Think of it like giving each user a visitor pass when they enter your website.
When they come back with that pass, you instantly know who they are and what they were doing.
Example:
- User logs in with their username and password.
- Server validates the credentials.
Server creates a session (an entry in memory or database) – e.g.
{ "session_id": "abc123", "user_id": "42", "name": "TheJat", "role": "admin" }Server sends a session cookie to the client:
Set-Cookie: session_id=abc123On every next request, browser automatically sends this cookie back:
Cookie: session_id=abc123- Server looks up the session ID, finds the user's data, and knows it's you.
The Problem with Multiple Servers (Stateful architecture)
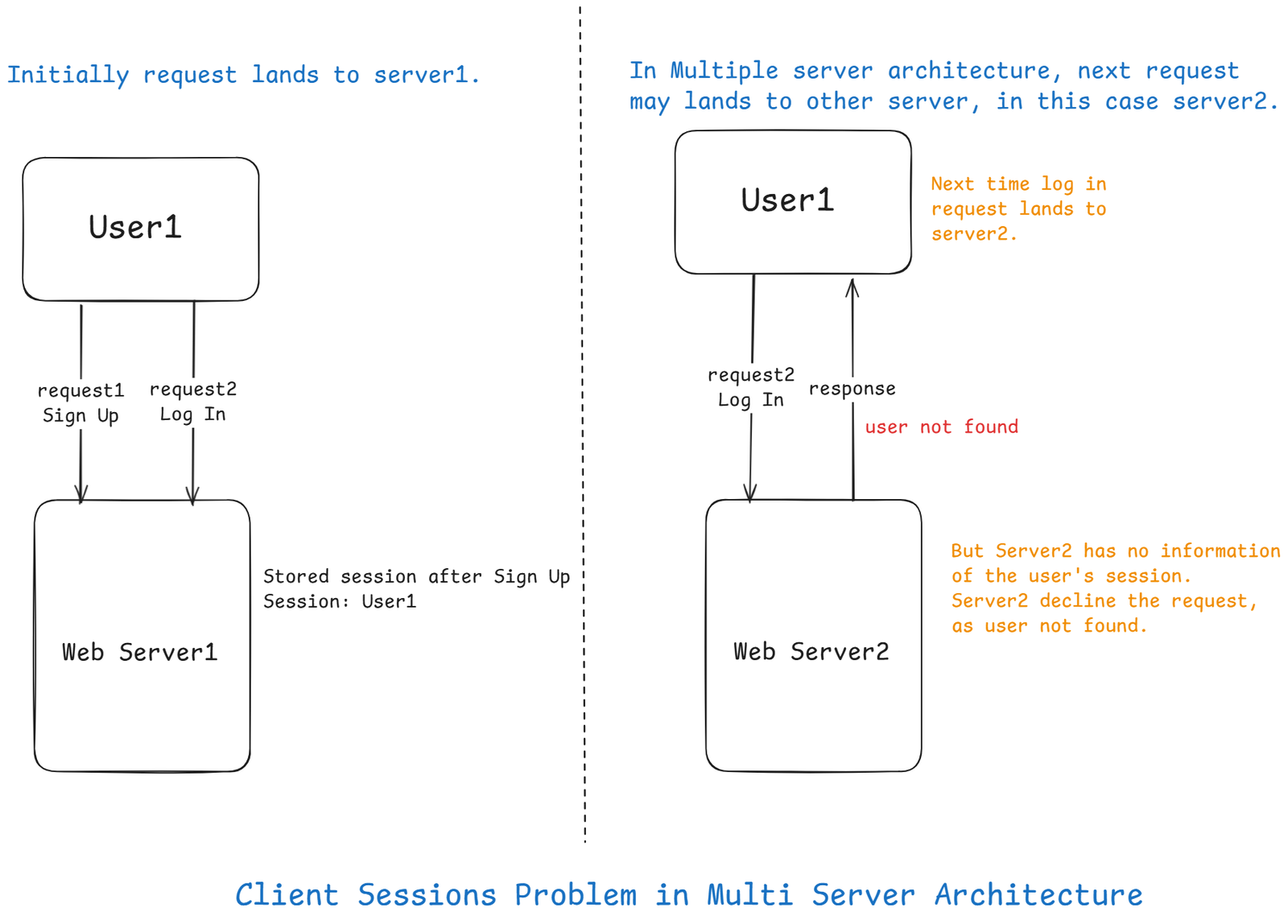
Now imagine this:
User1didsign upand its session is stored in Server A's memory.- Next request – the Load Balancer sends
User1to Server B. - Server B doesn't know who the
User1is.
And it will just give response of user not found.
That's session stickiness problem.
The issue is that every request from the same client must be routed to the same server.
Solutions to Handle Sessions in a Scaled System
1 Sticky Sessions (Session Affinity)
The load balancer “sticks” a user to the same server for the entire session.
So if you first landed on Server A, all your requests go to Server A until you log out.
Problems:
- Doesn't scale perfectly – if Server A crashes, the session is lost.
- Then user is forced to logout.
- Adding and removing servers is much more difficult with this approach.
- As existing users won't move to the new server because their sessions are already tied to older servers.
- So the new server gets very little traffic.
- Harder system maintenance
- If you want to restart a server, all users connected to that server lose sessions.
2 Centralized Session Store
Store session in a shared external store accessible to all web servers (e.g., Redis, Memcached, or Database).
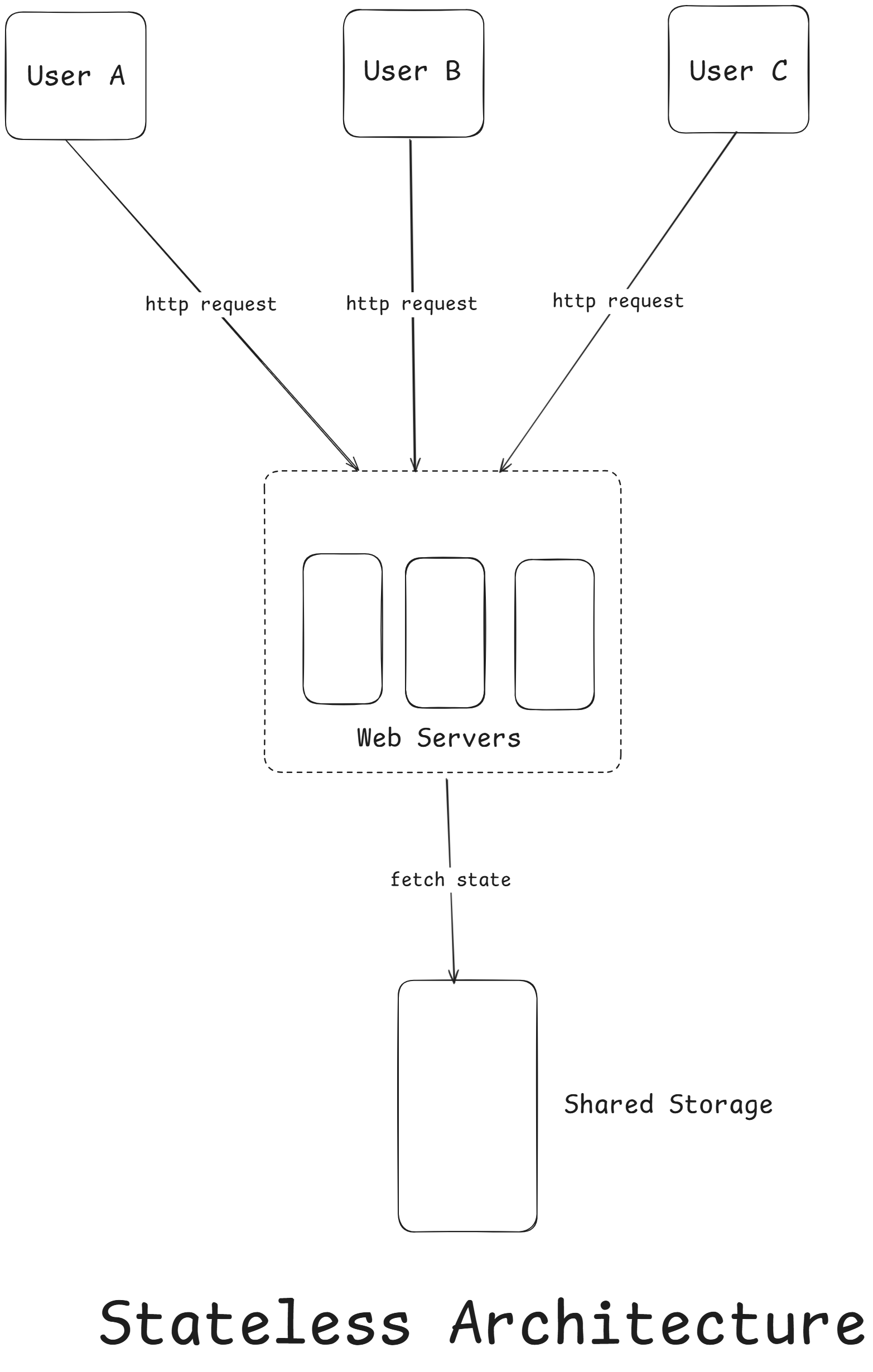
In this stateless architecture, HTTP requests from users can be sent to any web servers, which fetch state data from a shared data store. State data is stored in a shared data store and kept out of web servers.

As shown in the figure above, we move the session data out of the web tier and store them in the persistent data store. The shared data store could be a relational database, Memcached/Redis, NoSQL, etc. The NoSQL data store is chosen as it is easy to scale. Autoscaling means adding or removing web servers automatically based on traffic load. After the state data is removed out of web servers, auto-scaling of the web tier is easily achieved by adding or removing servers based on traffic load.
3 Token-Based Authentication (Stateless Sessions)
Instead of storing sessions on the server, the server issues a token (like a JWT – JSON Web Token) that contains user info and is self-validating.
Each request carries this token, and no session storage is needed.
Client → Login → Receives JWT
Client → Sends JWT with each request (Authorization: Bearer <token>)
Server → Verifies signature → Identifies user
Data Centers – Scaling Across the World
As our application, we have already:
- Split out web and database servers
- Added load balancers
- Implemented caching and CDN
- Built a stateless, horizontally scalable architecture
But what happens when users start coming from different parts of the world – New York, London, Mumbai, or Tokyo?
What Is a Data Center?
A data center is a physical facility that houses servers, databases, and networking equipment.
Think of it as the home of your application – the place where all your code runs and your user's data lives.
Every cloud provider (AWS, Google Cloud, Azure, etc.) has dozens of data centers across different regions of the world.
The Latency Problem
Let's say your only data center is in Mumbai, but your users are in New York.
When a New York user opens your website:
- Their request travels across the globe
- Hits your Mumbai servers
- Then the response travels back
This adds noticeable delay – known as latency.
Even a few hundred milliseconds of extra latency can make your site feel slow.
Solution: Deploy in Multiple Data Centers
To reduce latency and improve availability, large-scale systems replicate their application and data across multiple data centers.
Now you might have:
User (New York) -> US Data Center
User (London) -> Europe Data Center
User (Delhi) -> India Data CenterEach user is routed to the nearest data center, reducing response time dramatically.
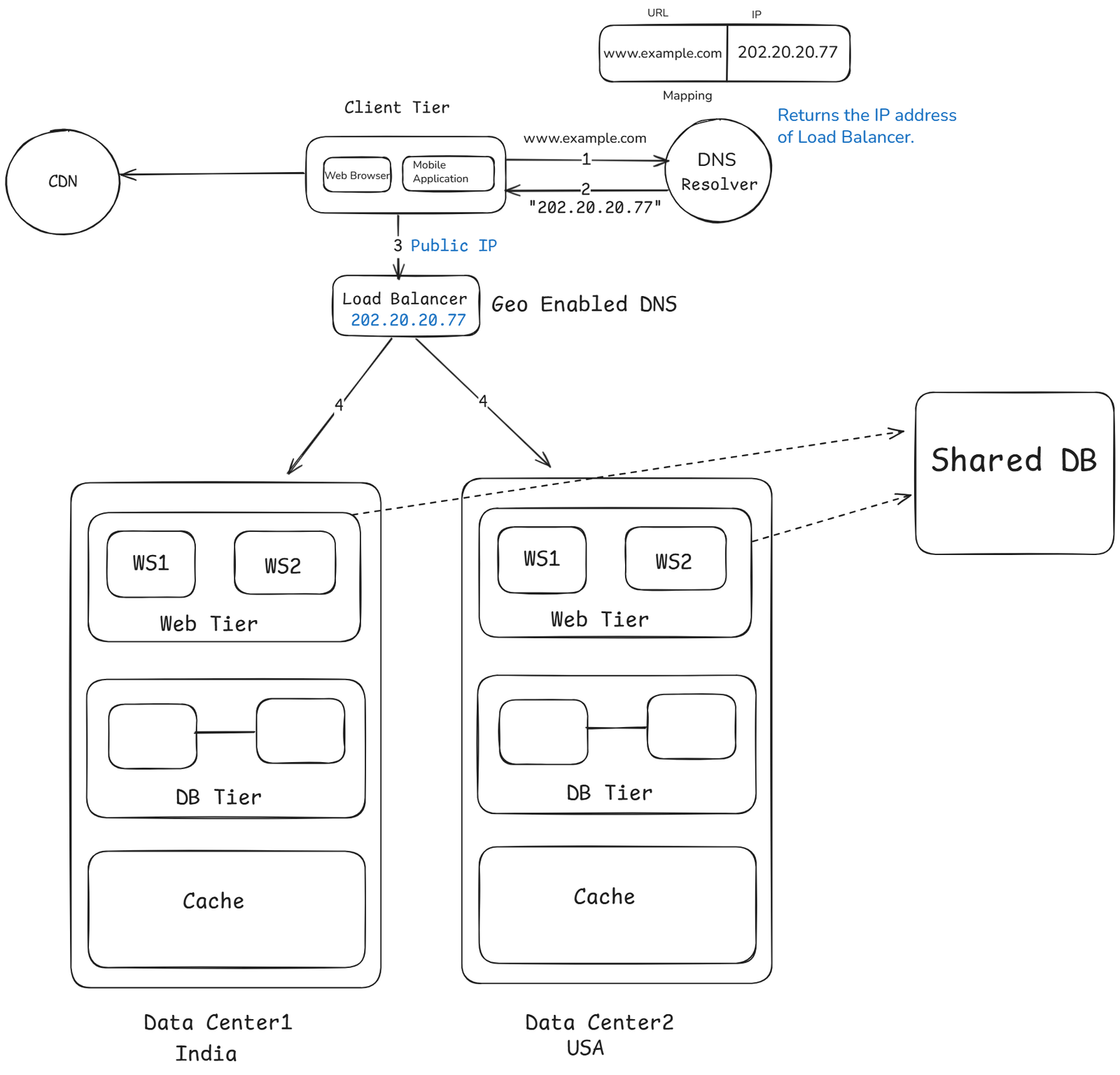
GeoDNS is a DNS service that allows domain names to be resolved to IP address based on the location of a user. In the event of any significant data center outage, we direct all traffic to a healthy data center.
How It Works
- Global Load Balancer (GSLB) detect user's location (using IP or geolocation)
- Routes the user to the nearest data center.
- CDN serves static assets (images, CSS, JS) from the nearest edge node.
- Database keeps data consistent via replication.
- If one data center goes down, traffic fails over to another automatically.
Technical Challenges must be resolved to achieve multi-data center setup:
- Traffic redirection: Effective tools are needed to direct traffic to the correct data center.
GeoDNScan be used to direct traffic to the nearest data center depending on where a user is located. - Data Synchronization: Users from different regions could use different local databases or caches. In failover cases, traffic might be routed to a data center where data is unavailable. A common strategy is to replicate data across multiple data centers.
- Test and deployment: With multi-data center setup, it is important to test your website/application at different locations.
Message Queue
As our system grows, our web servers are handling hundreds of thousands – maybe millions – of requests per second.
Each request might trigger heavy tasks such as:
- Sending emails
- Processing images or videos
- Updating analytics
- Writing multiple database entries
- Calling external APIs
If every web request tried to do all this work asynchronously, our users would face slow responses, and servers would be overloaded.
That's where Message Queues (MQ) comes in.
A message queue acts as a buffer between parts of the system – allowing one component to produce messages (tasks) and another to consume them asynchronously.
It let's your system say:
“I will handle this later.”
How a Message Queue Works
| Component | Role |
|---|---|
| Producer | The component that sends messages to the queue (e.g., web server). |
| Queue | Stores messages temporarily (like a buffer). |
| Consumer / Worker | The component that reads and processes messages. |
| Broker | The queue system itself (e.g., RabbitMQ, Kafka, SQS). |

- Producer = Web Server
- Queue = RabbitMQ / Kafka / SQS
- Consumer = Background Worker
Complete Architecture:
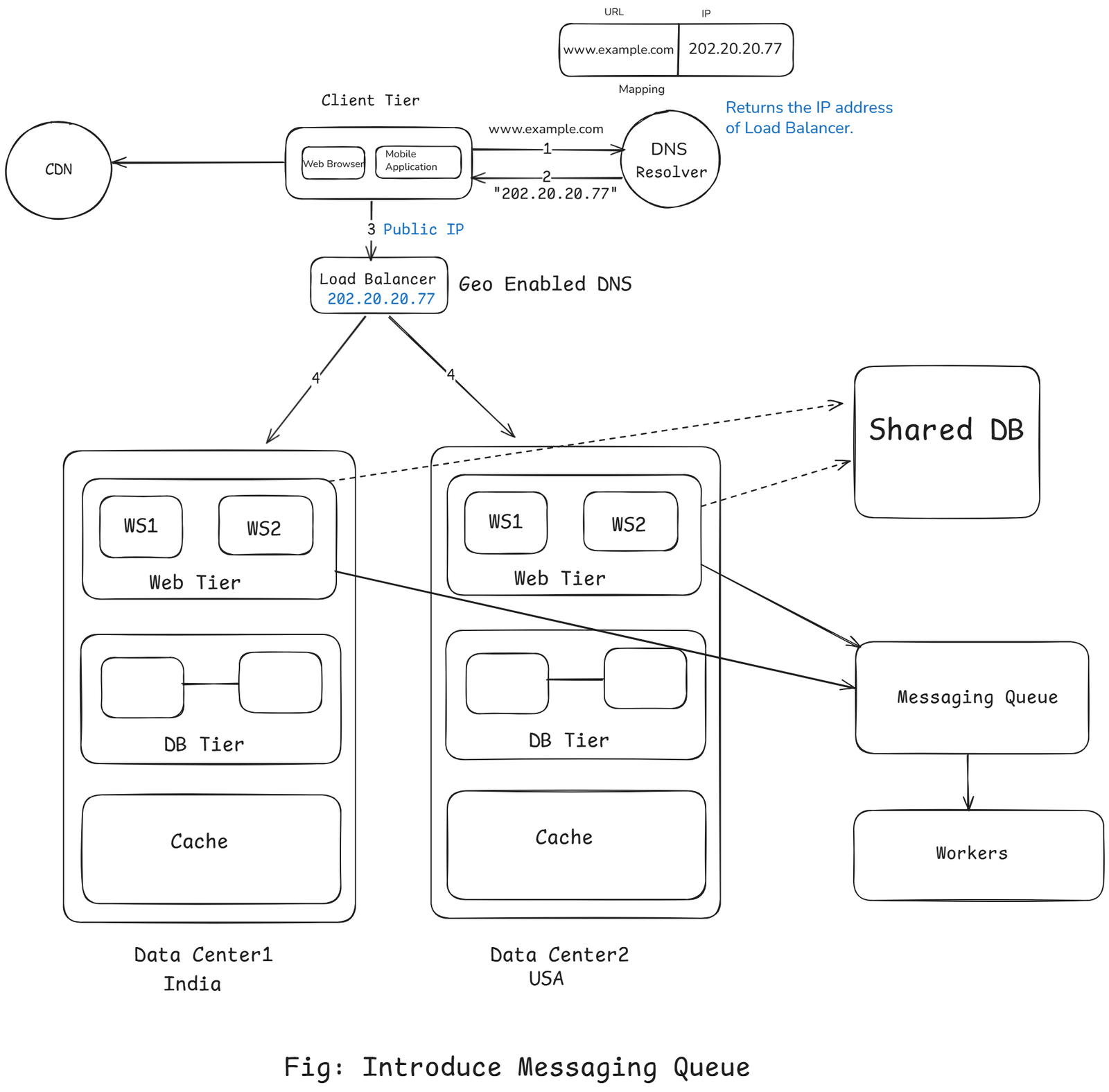
Database Partitioning
So far, we have scaled most components of our system except the database. One common approach to improve database performance is replication, where we use a master–slave architecture. In this setup, the master database handles write operations, while the slave databases handle read operations. This helps distribute the workload and improves read performance.
However, this approach has its limitations. In a master–slave architecture, the slave databases contain exact copies of the master’s data. Although this allows us to scale read operations, the write operations still depend on a single master database. As the number of users grows into the millions, this master database can become a bottleneck.
For example, suppose the master database can handle data for 10 million users. The slave databases also store the same data because they replicate the master. Even if we add multiple slaves, the total amount of data that the system can handle is still limited by the master database, since all writes must go through it.
Modern applications such as WhatsApp or YouTube serve hundreds of millions or even billions of users. A single database server cannot efficiently store and manage such massive amounts of data. Even with multiple slave replicas, the system will eventually reach the limits of the master server.
Therefore, just like application servers, databases also need to scale.
There are two main ways to scale a database:
- Vertical Scaling
- Horizontal Scaling
Vertical Scaling means increasing the resources of a single database server, such as adding more CPU, RAM, or storage. While this can improve performance, it has a limit because a single machine can only be upgraded up to a certain point. Additionally, vertical scaling can be expensive and may require downtime.
Horizontal Scaling, on the other hand, involves distributing the data across multiple database servers. Instead of storing all the data in one database, the data is partitioned (or sharded) and stored in different databases. Each database is responsible for a portion of the data.
For example, instead of storing all users in one database:
- Database 1 stores users with IDs
1-10 million - Database 2 stores users with IDs
10-20 million - Database 3 stores users with IDs
20-30 million
This approach allows the system to handle very large datasets and high traffic, because the workloads is distributed across multiple servers.
This technique is known as database partitioning or sharding, and it is widely used in large-scale systems to support millions or billions of users.

Leave a comment
Your email address will not be published. Required fields are marked *