
Load balancing is the process of distributing incoming requests across multiple servers so that no single server gets overwhelmed.
At the heart of it are algorithms that decide:
“Which server should handle this request?”
Why Load Balancing Matters
- Prevents server overload
- Improves response time
- Ensures high availability
- Enables horizontal scaling
Common Load Balancing Algorithms
In distributed system, a load balancer uses various load-balancing algorithms to efficiently distribute the incoming traffic across the multiple servers. load balancer employs one of the algorithm, factors like workload and configuration of the server, etc., based on which it picks the server to handle the request.
The primary goal is to maximize throughput, minimize response time, and avoid server overloading.
At high level the load balancing algorithm can be categorized into two:
1 Static Load Balancing Algorithms
These algorithms use predetermines rules that do not change in response to real-time metrices or server performance. They are often simple and predictable.
Examples are: Round Robin, Weighted Round Robin, Source IP Hashing, etc.
2 Dynamic Load Balancing Algorithms
These algorithms make decisions based on current, real-time data about server performance or load. They are more flexible and can adapt to fluctuations in workload.
Examples are: Least Connections, Weighted Least Connections, Least Response Time, etc.
1️⃣ Round Robin Algorithm
It is very simple load balancing algorithm, it direct client requests to different servers based on a rotating list. Load balancer maintains a list of available servers and directs incoming requests in a round robin fashion, like first request would be dispatched to first server, the second one to second server, and so on.
When the load balancer reaches the end of the list, it goes back to the beginning and start this cycle again.
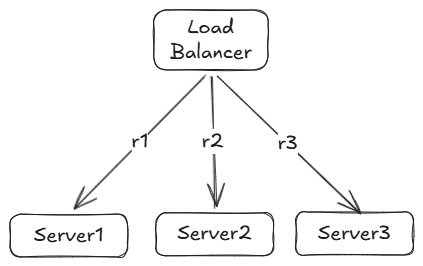
How It Works
- Sequential Assignment:
Each incoming request is assigned to the next server in a list, in a cyclic order. - Cycle Completion:
Once the algorithm reaches the last server in the list, it starts again with the first server. - Equal Distribution:
This rotation continues, ensuring that each server receives roughly the same number of requests over time.
Example
Imagine you have three servers—Server A, Server B, and Server C:
- The 1st request goes to Server A.
- The 2nd request goes to Server B.
- The 3rd request goes to Server C.
- The 4th request goes back to Server A, and so on.
Advantages
- Simplicity:
Easy to implement and understand. - Fairness:
Provides an even distribution of requests when servers have similar capacities.
Disadvantages
- Doesn't account the Load Awareness and server specification:
- It doesn't account for the current load or capacity differences among servers. If one server is slower or under heavier load, it still receives the same number of requests as others.
- As there is chances the some servers might be less resourceful, i.e., less processing speed or memory.
- The low-processing server may have the same load as a high-processing server.
- Static Distribution:
- It doesn't adapt to real-time performance metrics, which can lead to inefficiencies in heterogeneous environments.
2️⃣ Weighted Round Robin
The Weighted Round Robin (WRR) algorithm is an enhancement of the basic Round Robin method that takes server capacity or performance into account by assigning a weight to each server.
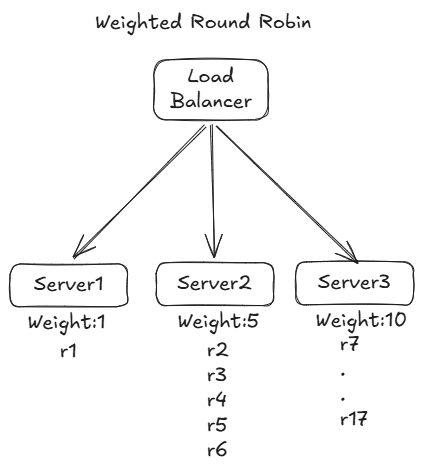
How It Works
- Assign Weights:
Each server in the pool is given a weight based on its capacity, processing power, or any other relevant metric. A higher weight indicates a higher capacity to handle more requests. - Distribute Requests:
- The algorithm iterates through the list of servers in a cyclic order.
- Instead of giving each server one request per cycle (as in basic Round Robin), each server receives a number of requests proportional to its weight.
- For example, if Server A has a weight of 3 and Server B has a weight of 1, then in a cycle of four requests, Server A might get three requests while Server B gets one.
- Cycle Completion:
Once the total number of requests equals the sum of the weights, the cycle starts over.
Example
Imagine you have three servers with the following weights:
- Server A: Weight 3
- Server B: Weight 2
- Server C: Weight 1
Over a complete cycle (total weight = 3 + 2 + 1 = 6 requests), the distribution might look like:
- Server A receives 3 requests.
- Server B receives 2 requests.
- Server C receives 1 request.
Advantages
- Load Awareness:
- WRR is better suited for heterogeneous environments where servers have different capacities, as it distributes requests in proportion to each server’s ability to handle them.
- Improved Performance:
- It helps balance the load more effectively compared to simple Round Robin, which treats all servers equally.
Disadvantages
- Static Weights:
- The algorithm uses predefined weights, which means it may not adapt to real-time changes in server performance or load. Dynamic adjustments would require additional monitoring and logic.
- Complexity:
- While still relatively straightforward, the addition of weights adds a layer of complexity compared to the basic Round Robin algorithm.
3️⃣ Random Load Balancing
This algorithms distribute the request on a random order.
How It Works
- Selection Process:
For every incoming request, the algorithm randomly selects one server from the pool of available servers. This decision is made without considering the current load or capacity of the servers. - Uniform Distribution:
Over a long period, if the random selection is uniform, the distribution of requests tends to balance out among the servers.
Variations
- Weighted Random:
In some cases, you might assign weights to servers based on their capacities. The algorithm then performs a weighted random selection, where servers with higher weights have a higher probability of being chosen.
Advantages
- Simplicity:
The random algorithm is easy to implement and requires minimal computation. - Low Overhead:
Since it doesn't require tracking server load or state, the overhead is minimal.
Disadvantages
- Lack of Awareness:
- It doesn’t consider real-time metrics such as current load, response times, or server health, which can lead to imbalances if servers are heterogeneous.
- Potential for Uneven Distribution:
- Although randomness can eventually even out, there might be short-term periods where some servers receive more requests than others.
4️⃣ Source IP Hash
The Source IP Hash algorithm is a load balancing strategy that uses the client's IP address to determine which backend server will handle the request. In other words, when a request arrives, the load balancer directs the request to a specific server based on the calculated hash value.
server = hash(key) % N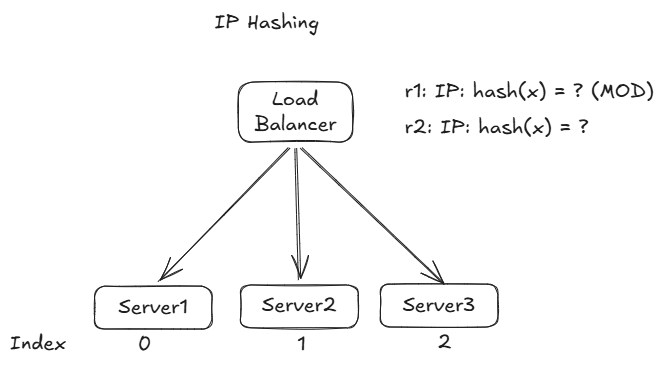
How It Works
- Hash Calculation:
The algorithm computes a hash value from the source IP address of the incoming request. This hash value is then used to map the request to a particular server in the pool. - Consistent Mapping:
By using the same hash function, the algorithm ensures that requests from the same client IP are consistently directed to the same server. This is particularly useful for session persistence (or "sticky sessions"), where it's important for a user to interact with the same server over multiple requests. - Server Selection:
Typically, the hash value is taken modulo the number of servers available, which determines the index of the server that should handle the request.
Advantages
- Session Persistence:
- Clients with the same IP address are consistently routed to the same server, which helps maintain session state without needing additional session management mechanisms.
- Simplicity:
- The algorithm is straightforward to implement and doesn't require complex state tracking or real-time performance metrics.
Disadvantages
- Uneven Distribution:
- If client IP addresses are not uniformly distributed, some servers may end up handling more traffic than others.
- Scalability Issues:
- Adding or removing servers can change the hash mapping significantly, potentially disrupting the consistency of session persistence unless additional techniques (like consistent hashing) are employed.
- Limited Granularity:
- In scenarios where many clients share the same public IP (for example, behind a NAT), the algorithm may not distribute load as evenly as desired.
- Each user will always get same server unless not using proxy (changed VPN).
- If we have the proxy in between the load balancer and the users then it fails, as we are getting the IP of the proxy and hash value would be same, so LB route all requests to same server.
5️⃣ URL Hash
The URL Hash Algorithm is a load balancing strategy that routes requests based on the hash value of the requested URL. Instead of relying on client IP or a simple rotation, it uses characteristics of the URL itself to determine which server will handle the request. Here’s how it works:
How It Works
- Hash Calculation:
The algorithm computes a hash from the URL (or a specific part of the URL, such as the path or query string). This hash value is used to consistently map the URL to a specific server. - Modulo Operation:
The computed hash is typically taken modulo the number of available servers. This operation yields an index that corresponds to a server in the pool. - Consistent Routing:
With this approach, requests for the same URL (or URL pattern) are consistently directed to the same server. This can be beneficial for caching and stateful applications, where it is advantageous for the same content or session to be handled by one server.
Advantages
- Cache Efficiency:
When servers cache responses for specific URLs, the URL hash ensures that subsequent requests for the same resource hit the same server, potentially increasing cache hit ratios. - Content-Based Routing:
It allows for routing decisions based on the actual content being requested rather than external factors, making it useful for distributed content delivery. - Session Persistence:
Similar to IP-based hashing, it offers a form of persistence by ensuring that requests for the same URL are handled by the same backend server.
Disadvantages
- Uneven Load Distribution:
If certain URLs are more popular than others, some servers might become overloaded while others remain underutilized. - Scalability Challenges:
Adding or removing servers can disrupt the hash mapping, potentially causing many URLs to be remapped to different servers. Techniques like consistent hashing can help mitigate this issue. - Limited Flexibility:
The approach is primarily effective when the URL is a good indicator of workload distribution. In dynamic environments with highly variable URL patterns, the benefits might be limited.
6️⃣ Least Connection Method
The Least Connection method is a dynamic load-balancing algorithm that directs incoming requests to the server with the fewest active connections at the moment.
How It Works
- Monitoring Active Connections:
Each server continuously tracks the number of active connections (or sessions) it is currently handling. - Evaluating Load:
When a new request arrives, the load balancer checks the active connection count for all available servers. - Server Selection:
The request is forwarded to the server with the smallest number of active connections, under the assumption that this server is the least busy and can handle the additional load more efficiently. - Dynamic Adaptation:
Since the active connection counts are updated in real time, the algorithm adapts to changes in traffic patterns and server load, ensuring a more even distribution of work.
Advantages
- Real-Time Load Awareness:
By considering the current number of active connections, the method helps prevent overloading a single server, especially when connections vary in duration or resource consumption. - Improved Resource Utilization:
Servers handling fewer requests are chosen more frequently, potentially leading to better overall performance and responsiveness. - Flexibility:
It works well in environments where the workload per connection is unpredictable or variable.
Disadvantages
- Stateful Connection Overhead:
If connections are long-lived or vary greatly in resource usage, simply counting active connections may not fully represent the server's load. - Implementation Complexity:
Requires continuous monitoring of each server’s active connections, which might add some overhead compared to simpler, static algorithms.
7️⃣ Weighted Least Connection
The Weighted Least Connection algorithm builds on the basic Least Connection method by considering each server's capacity through assigned weights.
How It Works
- Assigning Weights:
Each server is given a weight that reflects its processing power, capacity, or other performance metrics. For instance, a more powerful server might be assigned a higher weight than a less capable one. - Tracking Active Connections:
Every server continuously tracks the number of active connections it is handling. - Calculating Effective Load:
For each server, an effective load is calculated, typically by dividing the number of active connections by its weight. This gives a normalized measure of the load relative to its capacity. - Server Selection:
When a new request arrives, the algorithm selects the server with the lowest effective load. This ensures that servers with higher capacities (i.e., higher weights) are allowed to handle more connections while still being considered less loaded relative to their capability.
Example
Imagine three servers with the following characteristics:
- Server A: Weight 3, Active Connections: 6
Effective Load = 6 / 3 = 2 - Server B: Weight 2, Active Connections: 3
Effective Load = 3 / 2 = 1.5 - Server C: Weight 1, Active Connections: 1
Effective Load = 1 / 1 = 1
In this case, even though Server A has the highest absolute number of connections, its higher capacity means its effective load is balanced. However, Server C, with a lower weight, has a similar effective load relative to capacity. The algorithm would compare these ratios and assign the new request to the server with the lowest ratio.
Advantages
- Capacity-Aware Distribution:
By factoring in server weights, the algorithm ensures that more powerful servers receive a proportionally larger share of the load. - Better Resource Utilization:
This method optimizes resource use in heterogeneous environments where server capacities vary. - Dynamic Adaptation:
It adapts in real time to changes in server load, distributing new requests based on current performance metrics.
Disadvantages
- Weight Configuration:
Determining the correct weight for each server is crucial. Incorrect weighting can lead to suboptimal load distribution. - Complexity:
Compared to basic algorithms like round robin, it requires more sophisticated monitoring and computation.
8️⃣ Least Response Time
The Least Response Time algorithm is a dynamic load balancing strategy that directs incoming requests to the server that has exhibited the fastest response time based on recent performance metrics.
- Calculate TTFB (Time To First Byte): time interval between sending a request and receiving response from the server.
- Picks the server which has:
- active connections * least TTFB
- If it clashes, go with round robin
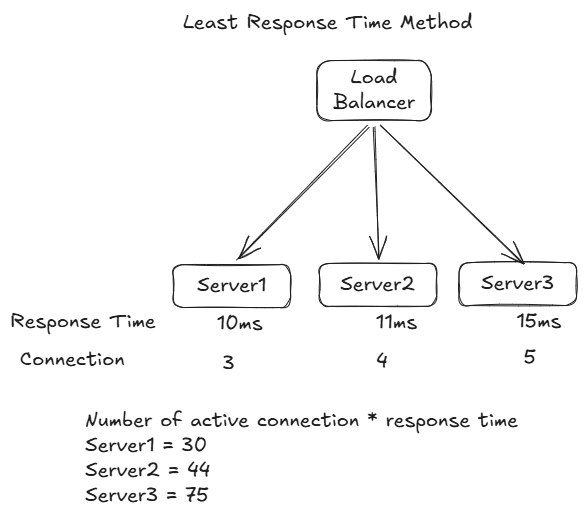
How It Works
- Performance Monitoring:
The system continuously tracks the response times of each backend server over a recent time window. These response times are collected from previous requests. - Server Evaluation:
When a new request comes in, the load balancer examines the average or current response times for all available servers. - Selection Process:
The request is then forwarded to the server with the lowest response time, on the assumption that this server is currently performing the best and can handle the new request quickly. - Dynamic Adaptation:
As server performance fluctuates due to load changes or resource availability, the response times are updated in real time. This ensures that the algorithm continually adapts to current conditions, always directing new requests to the fastest-responding server.
Advantages
- Optimized User Experience:
By routing requests to the server that responds the fastest, the algorithm helps reduce overall latency, leading to a more responsive experience for users. - Real-Time Adaptation:
The algorithm reacts to fluctuations in server performance, ensuring that the distribution of requests adapts to current conditions.
Disadvantages
- Measurement Overhead:
Constantly monitoring response times can introduce some overhead and may require sophisticated metrics collection. - Short-Term Variability:
Response times can fluctuate due to transient conditions, potentially causing the algorithm to make suboptimal decisions if not smoothed over an appropriate time window.
9️⃣ Resources Method
In the resource-based method, the load balancer distributes requests based on the current resource usage of servers, such as:
- CPU usage
- Memory usage
- Disk I/O
- Network bandwidth
Instead of static rules, decisions are based on live system health
How It Works
Agent are deployed to every server, which does Health Check, to check if the server is up. At a particular moment what is the capacity or load in that server.
Each server continuously reports is current state:
Server A → CPU: 80%, Memory: 70%
Server B → CPU: 30%, Memory: 40%
Server C → CPU: 50%, Memory: 60%When a request comes in:
- The load balancer analyzes metrics
- Choose the most available server
In this case: Server B
Load Balancer on Layer
1️⃣ Layer 7 Load Balancer (Application Layer)
Works at: HTTP/HTTPS level
How It Works:
At layer 7 load balancer inspects the actual request content, such as:
URL (/api/users)
Headers
Cookies
Query paramsExample:
GET /images → Server A
GET /api/users → Server BRouting based on request content.
2️⃣ Layer 3 Load Balancer (Network Layer)
Layer 3 corresponds to the IP layer in the OSI Model
A Layer 3 load balancer would:
- Route traffic based on IP addresses only
- Not consider ports (like L4) or content (like L7)
3️⃣ Layer 4 Load Balancer (Transport Layer)
Works at:
- TCP/UDP level
- Uses IP address and port
How It Works
A Layer 4 load balancer makes decision based on:
Source IP
Destination IP
Port
Protocol (TCP/UDP)It does Not look into the actual request content.
Example:
A request comes in:
IP: 192.168.1.10
Port: 443Load balancer forwards it to a backend server using:
- Round Robin
- Least Connections
4️⃣ Global Server Load Balancing (data centers) (GEO DNS)
It is a technique used to distribute user traffic across multiple geographically distributed data centers.
Modern applications run in multiple regions:
- Asia
- Europe
- US
Without GSLB:
- Users may connect to a faraway server
- High latency
- Poor experience
5️⃣ DNS Load Balancer
A DNS load balancer distributes user traffic by returning different IP addresses for the same domain name, effectively directing users to different servers or data centers.
It works at the DNS level, before a connection to any server is even established.
How It Works
When a user enters:
www.example.comUser's browser asks DNS resolver.
“What is the IP of this domain?”
- DNS load balancer decides which IP to return
- User connects directly to that server
Example:
www.example.com -> ?DNS may respond differently:
- User in India ->
1.1.1.1(Indian server) - User in US ->
2.2.2.2(US server)
Same domain, different response.
Types of Load Balancers: Hardware vs Software
Load balancers can broadly be classified into hardware-based and software-based solutions. The difference lies in how they are built, deployed, and scaled.
Hardware Load Balancer
A hardware load balancer is a physical device (appliance) dedicated to distributing network traffic.
Think of it as a specialized machine sitting in your data center.
How It Works:
- Installed in a data center
- Sits between users and servers
- Uses optimized hardware.
Examples:
- F5 Networks BIG-IP
- Citrix NetScaler
Advantages:
- High Performance
- Extremely fast (hardware acceleration)
- Reliability
- Built for enterprise-grade workloads
- Advanced Features
- SSL offloading
- DDoS protection
- Traffic inspection
Disadvantages:
- Expensive
- High upfront cost
- Maintenance cost
- Not flexible
- Hard to scale quickly
- Requires physical setup
Software Load Balancer
A software load balancer runs as an application on:
- Servers
- Virtual machines
- Containers
- Cloud platforms
How It Works
- Installed like normal software
- Uses system resources (CPU, memory)
Examples:
- NGINX
- HAProxy
- Amazon Web Services Elastic Load Balancer (ELB)
Advantages:
- Highly Flexible
- Easy to configure and deploy
- Scalable
- Can scale horizontally (add more instances)
- Cost-Effective
- No expensive hardware needed
- Cloud Friendly
- Works seamlessly in modern architectures
Disadvantages:
- Performance Limits
- Depends on underlying machine
- Resource Usage
- Consumes CPU, memory

Leave a comment
Your email address will not be published. Required fields are marked *