
Database replication is a core strategy in system design used to enhance data availability, fault tolerance, and scalability. It involves maintaining copies of a database on multiple servers, ensuring that data is duplicated and kept in sync across different locations.
What is Database Replication?
Database replication is the process of copying and maintaining database objects, such as tables and records, across multiple database servers. One server (often called the primary or master) serves as the source of data, while one or more secondary servers (replicas or slaves) maintain copies of this data. This setup ensures that if one server fails, other replicas can continue to serve data, thus enhancing system availability.
It is the process of keeping multiple copies of the same data in different servers (replicas) so that if one server goes down, other servers can continue to serve data without any interruption or downtime.
Why Database Replication ?
Suppose if there is an online store or anything that has a single database server that stores all the data related to customers. If this servers by any chance fails by issues like (hardware issues, software issues, etc.) then whole website would be unavailable.
To solve this kind of situation. The website owner can set up multiple database servers that replicate data from the primary database server. If the primary server goes down, other servers can take over and continue to serve requests.
Types of Database Replication
1️⃣ Master-Slave (Primary-Replica) Replication
One primary server (master) handles all write operations, while one or more secondary servers replicate data from the primary and handle read operations.
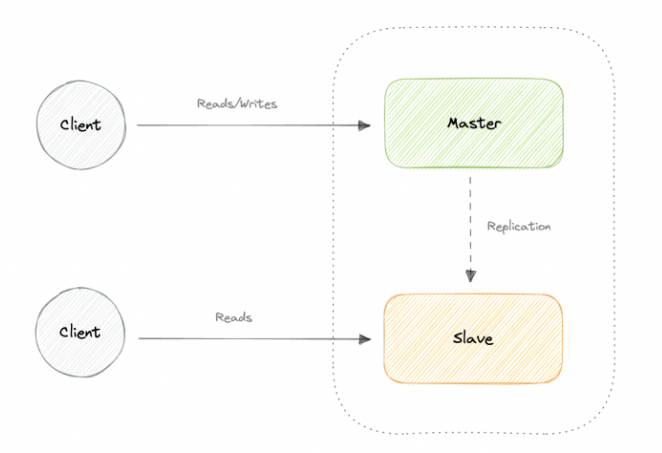
Use Cases:
Useful for read-heavy applications where write operations are relatively less frequent.
Advantages:
- Simplifies data consistency since the primary is the source of truth.
- Backups of the entire database of relatively no impact on the master.
- Applications can read from the slave(s) without impacting the master.
- Slaves can be taken offline and synced back to the master without any downtime.
Disadvantages:
- Replication adds more hardware and additional complexity.
- Downtime and possibly loss of data when a master fails.
- All writes also have to be made to the master in a master-slave architecture.
- The more read slaves, the more we have to replicate, which will increase replication lag.
Challenges:
- The primary server can become a bottleneck, and failover mechanisms are required to promote a replica if the primary fails.
2️⃣ Master-Master (Multi-Master) Replication
Multiple servers act as masters and can write operations. Changes are synchronized between all masters. If either master goes down, the system can continue to operate with both reads and writes.
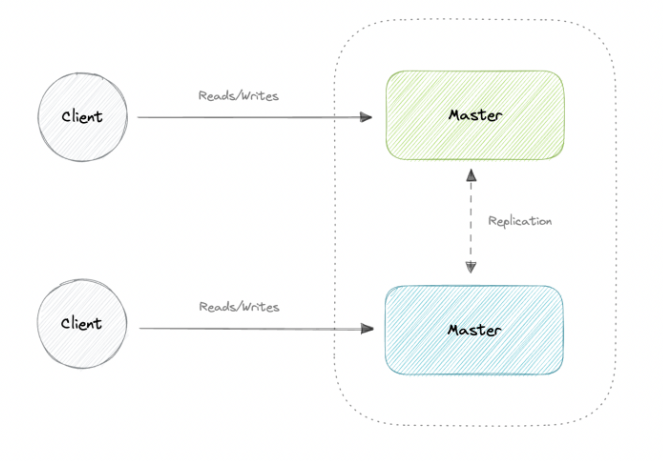
Use Cases:
Suitable for distributed systems where write occur in multiple locations.
Advantages:
- Improves write scalability and offers better tolerance.
- Applications can read from both masters.
- Distributes write load across both master nodes.
- Simple, automatic, and quick failover.
Disadvantages:
- Not as simple as master-slave to configure and deploy.
- Either loosely consistent or have increased write latency due to synchronization.
- Conflict resolution comes into play as more write nodes are added and as latency increases.
Challenges:
Conflict resolution is required when the same data is modified concurrently on different masters.

Leave a comment
Your email address will not be published. Required fields are marked *