
Overview
Hash maps, also known as hash tables or associative arrays, are a popular data structure in computer science used to store key-value pairs. They provide efficient insertion, deletion, and lookup operations. A hash map (hash table) allows us to quickly look up a key (often a string) to find its corresponding value (any data type). Under the hood, they are arrays that are indexed by a hash function of the key. In C++, the std::unordered_map class provides an implementation of a hash map.

What is a hash map?
A hashmap is an associative container that stores elements in a key-value format. It utilizes a hash function to map keys to indices in an array, known as a bucket. This hashing technique allows for fast retrieval of values based on their associated keys. In C++, hash maps are implemented using the unordered_map container class from the Standard Template Library (STL).
- Hash map (also, hash table) is a data structure that basically maps keys to values.
- It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
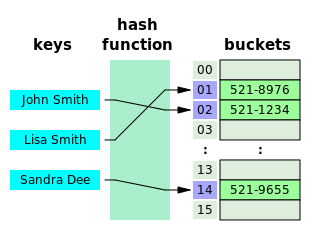
Every Language has its own implementation and nomenclature for it:
Python - Dictionary
Java -HashMap
JavaScript - Object
Golang - MapWhat is Hashing?
Hashing is the process of converting input data of arbitrary (Something that's arbitrary seems like it's chosen at random) size into a fixed-size value, typically a numerical value, using a hash function. The output value is called a hash code or hash value.
How Hashing Works:
- Hash Function:
- A hash function takes an input (or 'message') and returns a fixed-size string of bytes. The output is typically a short, fixed-length hash value.
- The input to the hash function can be of any size, but the output is always of fixed size.
- The output is typically a hash code, hash value, or simply, a hash.
- There is no standard hash function, means we can develop the hash function according to the general expected characteristics of our data inputs.
- Hash Code:
- The hash code is a unique value generated by the hash function for a given input.
- Even a small change in the input data should produce a significantly different hash code.
- Collision:
- A collision occurs when two different inputs produce the same hash code.
- A good hash function minimizes the likelihood of collisions.
Hashing Techniques:
There are two main hashing techniques:
- Direct Addressing: In direct addressing, the key itself is used as an index to access the data directly in an array. This works well when the keys are small integers or can be easily mapped to small integers.
Suppose we have an array arr of size 10, and we want to store the following key-value pairs:
Key: 3, Value: "Alice"
Key: 7, Value: "Bob"
Key: 5, Value: "Charlie"Index: 0 1 2 3 4 5 6 7 8 9
----------------------------------------------------------
Value: - - - - - - - - - -
After inserting the key-value pairs using direct addressing:
Index: 0 1 2 3 4 5 6 7 8 9
---------------------------------------------------------------------
Value: - - - Alice - Charlie - Bob -
-
- Hash Tables: Hash tables use a hash function to map keys to indices in an array. They offer fast average-case time complexity for insertion, deletion, and lookup operations, typically
O(1).
Suppose we have a hash table table of size 10, and we want to store the same key-value pairs:
Key: 3, Value: "Alice"
Key: 7, Value: "Bob"
Key: 5, Value: "Charlie"Index: 0 1 2 3 4 5 6 7 8 9
----------------------------------------------------------
Value: - - - - - - - - - -
We will use the following hash function to calculate the index:
index = key % 10
After inserting the key-value pairs using a hash function:
Index: 0 1 2 3 4 5 6 7 8 9
----------------------------------------------------------
Value: - - - Alice - Charlie - Bob -
Comparison Between them:
- Direct Addressing:
- Pros: Direct and simple. No need for a hash function.
- Cons: Requires a large array if keys are large or unbounded.
- Hash Tables:
- Pros: Efficient use of memory. Works well for a large number of keys.
- Cons: Requires a good hash function. May lead to collisions.
How do Hash Tables Work?
1 Storing:
[a] Hash Function:
- A hash function is used to convert keys into indexes. It takes a key as input and returns a hash code, which is typically an integer.
When a key is inserted into the hash table, a hash function is applied it the kye to compute its hash code.
For example, let's say we have a key “Alice”. We apply a hash function to "Alice" and get its hash code.
Hash Function
|
v
"Alice"
|
v
Hash Code
[b] Hash Code to Index Calculation:
Once we have the hash code, we use it to determine the index in the array where the key-value pair will be stored. This is usually done by taking the modulus of the hash code with the size of the array.
For example, if our hash code is 7 and the size of the array is 5, we calculate the index as 7 % 5 = 2.
Hash Code
|
v
Index
Let's pull it all together:
Hash Function Index Calculation
| |
v v
"Alice" Hash Code % Array Size
| |
v v
Hash Code Index
| |
v v
7 2
This index (2) determines where the key-value pair "Alice" will be stored in the underlying array.
[c] Storing the Key-Value Pair:
Once we have the index, we store the key-value pair at that index of underlying array.
Index
|
v
+---+---+---+---+---+
| | | | | |
+---+---+---+---+---+
| | |Alice| | |
+---+---+---+---+---+
2 Retrieval:
When we want to retrieve the value associated with a key, we follow these steps:
[a] Hash Function:
When a key is inserted into the hash table, a hash function is applied to the key to compute its hash code.
For example, let's say we have a key "Alice". We apply a hash function to "Alice" and get its hash code.
Hash Function
|
v
"Alice"
|
v
Hash Code
[b] Calculate the Index:
We apply the same hash function to the key to calculate its hash code. Then we calculate the index using the hash code.
Hash Function
|
v
"Alice"
|
v
Hash Code
|
v
Index
|
v
2
[c] Retrieve the Value:
We look up the index in the array and retrieve the value associated with the key.
Index
|
v
+---+---+---+---+---+
| | | | | |
+---+---+---+---+---+
| | |Alice| | |
+---+---+---+---+---+
|
v
Value
Putting it all together:
Retrieval Process
|
v
"Alice"
|
v
Hash Code
|
v
Index
|
v
+---+---+---+---+---+
| | | | | |
+---+---+---+---+---+
| | |Alice| | |
+---+---+---+---+---+
|
v
Value
- Collision Handling:
- Collisions occur when two or more keys map to the same index. There are several techniques to handle collisions:
- Chaining: Each bucket in the hash table is a linked list. Colliding keys are stored in the same bucket as a linked list.
- Open Addressing: If a collision occurs, the algorithm tries to find the next available slot in the table.
- Collisions occur when two or more keys map to the same index. There are several techniques to handle collisions:
- Insertion, Deletion, and Lookup:
- Hash Tables are designed to provide constant time insertions, deletions, lookups.
- To insert a key-value pair into a hash table, the key is hashed to determine the index, and the value is stored at that index.
- To delete a key-value pair, the key is hashed to find the index, and the value at that index is removed.
- To look up a value, the key is hashed to find the index, and the value at that index is returned.
Construction of Hash Table
Hash Table are constructed with two basic foundational ideas.
- Map application key to hash key
“apple” → 136027 - Map hash key to a smaller range
136027 → 08
Components of a Hash Table
- Array: The underlying data structure of a hash table is typically an array of fixed size. The size of this array is determined when the hash table is created.
- Hash Function: A hash function is a mathematical function that converts a key into an index within the range of the array. The goal of the hash function is to evenly distribute keys across the array to minimize collisions.
- Key-Value Pairs: Key-value pairs are the data that are stored in the hash table. Each key is unique within the hash table, and the value is associated with that key.
- Bucket (or Slot):Each index in the array is called a bucket or slot. Each bucket can store one or more key-value pairs. In case of collision, multiple key-value pairs can be stored in the same bucket using techniques like chaining or open addressing.
- Collision Resolution: Collisions occur when two different keys hash to the same index in the array. Collision resolution techniques are used to handle collisions:
- Chaining: In chaining, each bucket contains a linked list of key-value pairs that have the same hash code. When a collision occurs, the new key-value pair is appended to the linked list at that index.
- Open Addressing: In open addressing, when a collision occurs, the algorithm searches for the next available slot in the array using a probing sequence. Common probing sequences include linear probing, quadratic probing, and double hashing.
- Load Factor: The load factor of a hash table is the ratio of the number of elements stored in the hash table to the size of the array. It determines when the hash table should be resized. When the load factor exceeds a threshold (commonly 0.7), the hash table is resized to maintain efficiency.
- Automatic Resizing: As the number of elements in the hash table increases, the likelihood of collisions also increases, which can degrade performance. To maintain efficiency, hash tables automatically resize themselves by doubling their size and rehashing all elements when the load factor threshold is reached.
Example:
Let's say we have a hash table of size 10:
Array size: 10We use the following hash function to calculate the index:
index = hash(key) % 10
If we insert a key-value pair with the key "John", and the hash function calculates the hash code hash("John") = 7, then the index would be 7 % 10 = 7, and the key-value pair would be stored at index 7 in the array.
If we insert another key-value pair with the key "Alice", and the hash function calculates the hash code hash("Alice") = 7, and we're using chaining to resolve collisions, then we would create a linked list at index 7 and store both key-value pairs in the linked list.
Hash Table Collisions and Resolutions
In hash tables, collisions occur when two different keys generate the same index (hash code) in the underlying array. Collisions are inevitable because the numbers of possible keys is typically much larger than the number of indices in the array. Therefore, it's essential to have mechanisms to handle collisions.
There are mainly two approaches to handle collisions in hash tables:
- Chaining
- Open Addressing
1 Chaining:
In chaining, each bucket in the hash table array is a linked list of key-value pairs. When a collision occurs, meaning multiple keys hash to the same index, the new key-value pair is simply appended to the linked list at that index.
The value is added as the next node of the list.

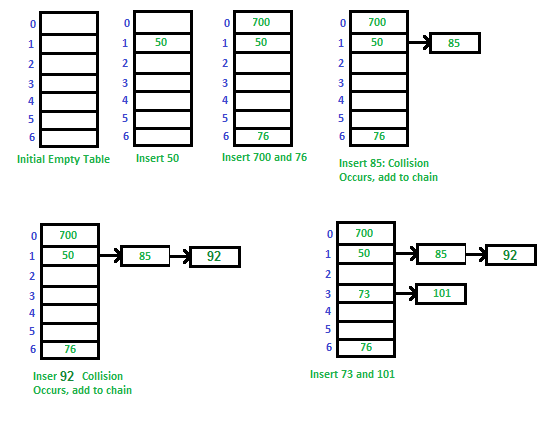
- Advantages:
- Simple to implement.
- Hash table never fills up, we can always add more elements to the chain.
- Less sensitive to the hash function or load factors.
- It is mostly used when it is unknown how many and how frequently keys may be inserted or deleted.
- Disadvantages:
- The cache performance of chaining is not good as keys are stored using a linked list. Open addressing provides better cache performance as everything is stored in the same table.
- Wastage of Space (Some Parts of the hash table are never used)
If the chain becomes long, then search time can become O(n) in the worst case - Uses extra space for links.
2 Open Addressing:
In open addressing, when a collision occurs, the algorithm searches for the next available slot (probing) in the array and stores the key-value pair there. There are several methods for probing, including linear probing, quadratic probing, and double hashing.

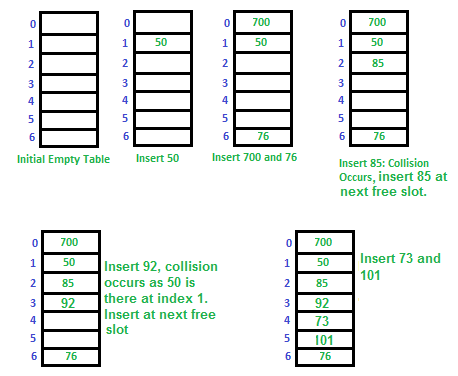
Open Addressing involves finding an alternative slot (probing) when a collision occurs. Common probing sequences include:
1 Linear Probing: Search for the next available slot by incrementing the index linearly. If that slot is also occupied, the algorithm continues searching for the next available slot until an empty slot is found. This process is repeated until all collided keys have been stored. Linear probing has the best cache performance but suffers from clustering.
index = (hash(key) + i) % table_size
Where:
hash(key)is the hash code of the key.iis the probe number.table_sizeis the size of the hash table.
Example:
Suppose we have a hash table of size 10 and want to insert the following key-value pairs:
Key: "John" (hash code = 4)
Key: "Alice" (hash code = 4, collision with "John")
Key: "Bob" (hash code = 3)We will use the following hash function:
hash(key) = key.length() % 10
Now, let's calculate the indices using linear probing:
Key: "John"
Hash code = 4
Index = (4 + 0) % 10 = 4 (No collision)
Key: "Alice"
Hash code = 4
Index = (4 + 0) % 10 = 4 (Collision with "John")
Now, we increment i and re-calculate:
Index = (4 + 1) % 10 = 5
Key: "Bob"
Hash code = 3
Index = (3 + 0) % 10 = 3 (No collision)After inserting these key-value pairs using linear probing:
Index 0: Empty
Index 1: Empty
Index 2: Empty
Index 3: Bob
Index 4: John
Index 5: Alice
Index 6: Empty
Index 7: Empty
Index 8: Empty
Index 9: Empty
2 Quadratic Probing: Search for the next available slot using a quadratic function. When a collision occurs, the algorithm looks for the next slot using an equation that involves the original hash value and a quadratic function. If that slot is also occupied, the algorithm increments the value of the quadratic function and tries again. This process is repeated until an empty slot is found. Quadratic probing lies between the two in terms of cache performance and clustering.
index = (hash(key) + c1 * i + c2 * i^2) % table_size
Where:
hash(key)is the hash code of the key.iis the probe number.c1andc2are constants.table_sizeis the size of the hash table.
3 Double Hashing: Use a second hash function to calculate the step size for probing. The algorithm uses a second hash function to determine the next slot to check when a collision occurs. The algorithm calculates a hash value using the original hash function, then uses the second hash function to calculate an offset. The algorithm then checks the slot that is the sum of the original hash value and the offset. If that slot is occupied, the algorithm increments the offset and tries again. This process is repeated until an empty slot is found. Double hashing has poor cache performance but no clustering. Double hashing requires more computation time as two hash functions need to be computed.
index = (hash1(key) + i * hash2(key)) % table_size
Where:
hash1(key)andhash2(key)are two different hash functions.iis the probe number.table_sizeis the size of the hash table.
Hash Function
A hash function is a mathematical function that takes an input (or "key") and produces a fixed-size integer value, called a hash code or hash value. The purpose of a hash function in a hash table is to map keys to indices of an array, allowing for efficient storage and retrieval of key-value pairs. Here are the characteristics of a good hash function:
- Deterministic: For the same input, a hash function should always produce the same hash code.
- Uniform Distribution: A good hash function should distribute keys uniformly across the entire range of hash codes. This helps minimize collisions and ensures that each bucket in the hash table has a roughly equal number of elements.
- Fast Computation: The hash function should be computationally efficient, allowing for fast insertion, deletion, and lookup operations.
- Minimal Collisions: While collisions are inevitable, a good hash function should aim to minimize them by spreading out keys as evenly as possible across the hash table.
- Minimal Data Sensitivity: Small changes in the input should result in large changes in the hash code to reduce clustering.
Example Hash Function:
A simple example of a hash function for strings might be:
unsigned int hashFunction(const std::string& key, int tableSize) {
unsigned int hashValue = 0;
for (char ch : key) {
hashValue = 37 * hashValue + ch; // A simple hash function
}
return hashValue % tableSize; // Reduce hash value to fit within table size
}
- We initialize hashValue to 0.
- For each character in the input string, we multiply the current hash value by 37 and add the ASCII value of the character.
- Finally, we take the result modulo tableSize to ensure that the hash value fits within the range of indices in the hash table.
Usage:
std::string key = "Alice";
int tableSize = 10;
unsigned int index = hashFunction(key, tableSize);
In this example, the index calculated using the hash function would determine where the key "Alice" is stored in the hash table.
unordered_map C++
unordered_map is an associated container that stores elements formed by the combination of a key value and a mapped value. The key value is used to uniquely identify the element and the mapped value is the content associated with the key. Both key and value can be of any type predefined or user-defined.
In simple terms, an unordered_map is like a data structure of dictionary type that stores elements in itself.
Internally unordered_map is implemented using Hash Table, the key provided to map is hashed into indices of a hash table which is why the performance of data structure depends on the hash function a lot but on average, the cost of search, insert, and delete from the hash table is O(1).
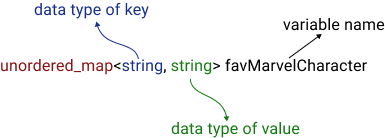
Syntax:
#include <unordered_map>
std::unordered_map<Key, T> name;
Key: The type of the keys in the map.T: The type of the mapped value.name: The name of the unordered_map.
If you need to store the frequency of characters in a word, you can do so in the array. Suppose the input word is “ababccddef” and you want to count the occurrence of every alphabet in the word.
#include <iostream>
#include <unordered_map>
#include <string>
using namespace std;
// Class representing a hash table
class FrequencyCounter {
private:
// Array to store the frequency of characters
int frequency[26] = {0};
// Function to convert a character to its index in the frequency array
int getIndex(char ch) {
return ch - 'a';
}
public:
// Constructor
FrequencyCounter() {}
// Destructor
~FrequencyCounter() {}
// Function to update the frequency of characters
void update(const string& word) {
for (char ch : word) {
if (isalpha(ch)) {
ch = tolower(ch);
frequency[getIndex(ch)]++;
}
}
}
// Function to display the frequency of characters
void display() {
for (int i = 0; i < 26; ++i) {
char ch = 'a' + i;
cout << ch << ": " << frequency[i] << endl;
}
}
};
int main() {
// Create a frequency counter
FrequencyCounter counter;
// Input word
string word = "Hello, World!";
// Update frequency counter
counter.update(word);
// Display frequency of characters
counter.display();
return 0;
}
But if you need to count the frequency of words in a statement like “mera naam mera kaam”, here mera is twice in frequency while rest are single in occurrence. You can use the above method for it, you would need unordered_map for it to store the data in key-value form. where key would be the word as string, and value be the frequency as integer.
#include <iostream>
#include <unordered_map>
#include <string>
#include <sstream>
using namespace std;
// Class representing a word frequency counter
class FrequencyCounter {
private:
// Hash map to store the frequency of words
unordered_map<string, int> frequency;
public:
// Constructor
FrequencyCounter() {}
// Destructor
~FrequencyCounter() {}
// Function to update the frequency of words
void update(const string& statement) {
// Create a stringstream to extract words from the statement
stringstream ss(statement);
string word;
// Update the frequency of each word
while (ss >> word) {
frequency[word]++;
}
}
// Function to display the frequency of words
void display() {
for (const auto& pair : frequency) {
cout << pair.first << ": " << pair.second << endl;
}
}
};
int main() {
// Create a frequency counter
FrequencyCounter counter;
// Input statement
string statement = "Hello, World! Hello, C++ World!";
// Update frequency counter
counter.update(statement);
// Display frequency of words
counter.display();
return 0;
}

Leave a comment
Your email address will not be published. Required fields are marked *