Data Partitioning
It is a technique to break up a database into many smaller parts. It is the process of splitting up a database or a table across multiple machines to improve the manageability, performance, and availability of a database.
Partitioning a large dataset into several small partitions placed on different machines.
Problem
Before partitioning, databases often operated as large, monolithic structures where all the data resides in a single table or a few tables. This design created several challenges:
- Performance Issues:
- As the volume of data grew, every query – whether it needed just a small subset or the entire dataset – had to scan through the entire table. This led to slower query response times and increased I/O overhead.
- Scalability Constraints:
- A single, monolithic database can become a bottleneck as data grows, making it difficult to distribute the load or scale horizontally across multiple servers. This limited the database’s ability to handle increased user demand or larger datasets efficiently.
- As with data increases the database server starts running out of disk at some point.
- A single, monolithic database can become a bottleneck as data grows, making it difficult to distribute the load or scale horizontally across multiple servers. This limited the database’s ability to handle increased user demand or larger datasets efficiently.
- Maintenance Difficulties:
- Managing backups, index rebuilds, and data archiving for a large unpartitioned table can be cumbersome and time-consuming. The impact of maintenance tasks on system performance was significant because they had to deal with the full dataset all at once.
- Fault Tolerance and Isolation:
- In a non-partitioned system, a failure in one part of the database (such as corruption or hardware issues) could potentially affect the entire system, as there was no natural separation of data to isolate problems.
Database partition helps us fix all the above challenges by distributing data across several partitions. Each partition may reside on the same machine or different machines.
When to Partition a Table?
Partitioning a table is generally considered when you encounter certain performance, scalability, and manageability challenges. Here are some key situations and considerations for when to partition a table:
When to Partition a Table
- Large Data Volumes:
If your table grows into millions or billions of rows, scanning the entire table for queries can become inefficient. Partitioning limits the amount of data processed by queries that target specific segments (e.g., recent orders, specific regions). - Query Performance Issues:
When queries consistently experience slow response times due to scanning large datasets—even with indexing—partitioning can help by allowing queries to target only relevant partitions. - Maintenance Challenges:
For tasks such as backups, index rebuilding, or archiving, managing one enormous table can lead to long maintenance windows. Partitioning allows you to perform these operations on smaller, more manageable pieces of data without impacting the entire table. - Access Pattern Segmentation:
If your queries frequently filter data based on a particular column (like a date, region, or user ID), partitioning by that column can enhance performance. For example, partitioning a transactions table by date lets you quickly isolate recent activity without scanning historical data. - Load Distribution and Scalability:
In distributed database systems, partitioning (or sharding) helps distribute data across multiple servers, enabling horizontal scaling and reducing the load on any single node. - Fault Isolation:
Partitioning can improve fault tolerance. If one partition experiences corruption or hardware issues, only that segment is affected rather than the entire dataset.
Real-World Example
Imagine a social media platform that stores billions of user posts in one table. As the platform grows, querying recent posts for a trending topic becomes slow because the database must scan an enormous table. By partitioning the table based on a time-based criterion (e.g., month or week), the system can quickly retrieve posts from the relevant partition. This not only speeds up queries but also simplifies maintenance tasks like archiving older posts or rebuilding indexes for specific time periods.
Data Partitioning Methods
Data partitioning methods are techniques used to divide a dataset into distinct segments to improve performance, scalability, and manageability. Here’s an overview of the most common methods:
1️⃣ Horizontal Partitioning (Sharding)
In this we split the table data horizontally based on the range of values defined by the partition key. It is also referred to as database sharding.
Divides a table into multiple subsets of rows, each containing the same columns.
Each partition holds a subset of the rows based on a defined criterion such as a range of IDs, dates, or geographic regions. The partition key is responsible for distributing the data among all the partitions. When a query is made using the partition key, the database will determine which partition it needs to query.
Use Case:
- For an e-commerce site, orders might be split into different partitions by order date, so recent orders are stored separately from older ones, speeding up queries for current activity.
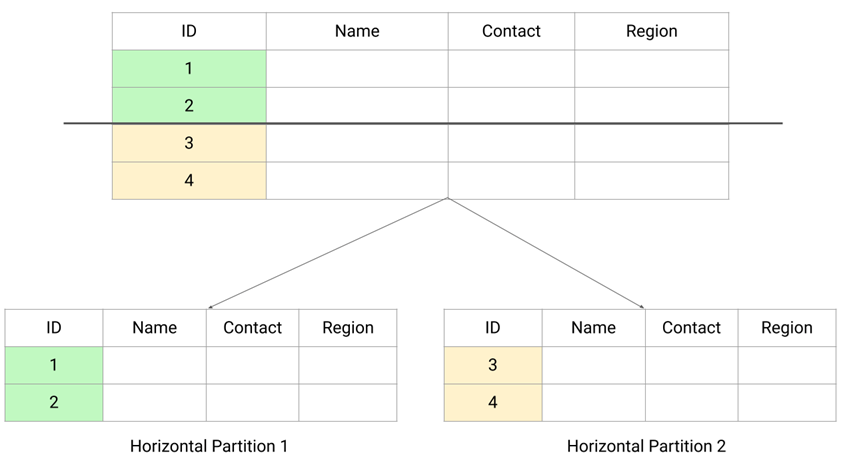
Suppose there is a large database containing multiple rows of customer data that has a slow query performance. So we can think of partitioning the table into two separate table horizontally. The first table would contain the first half of the customer data, and the second table would contain the second half. Now query will go to either partition 1 or partition 2, depending on the partition key. For example, suppose we store the contact details for customers. In that case, we can keep the contact info starting with the name A-H on one partition and contact info starting with the name I-Z on another partition.
Disadvantages:
- Data may not be evenly distributed across the partitions. For example, if there are many more customers with names that fall in the range of
A-Hthan in the rangeI-Z, the first partition may experience a much heavier load than the second partition.
2️⃣ Vertical Partitioning
Vertical partitioning (also known as normalization) divides a table into smaller tables based on columns. Each new table contains a subset of the original columns, usually grouping together columns that are frequently accessed together.
- Each partitioned table retains the primary key or a unique identifier from the original table, ensuring the data can be reassembled or related via joins.
Frequently accessed columns or those with heavy read/write activity are separated from less frequently used data.
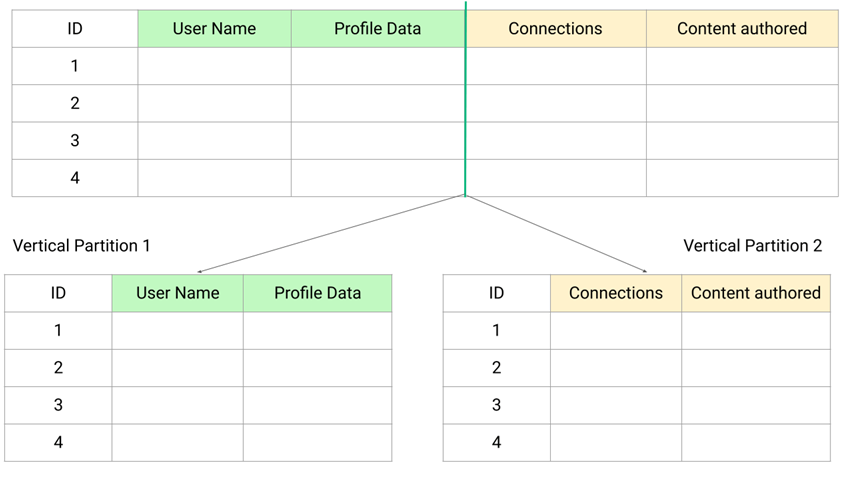
Real-World Example
Imagine a user profile table in a social media that originally contains 20 columns, including basic information like userID, Name, Email, and less frequently accessed details like Preferences, Activity, Logs, and Profile Settings.
- Before Vertical Partitioning:
All columns are stored together in one table. A query that only needs to display basic profile details (e.g.,UserID,Name,Email) would have to scan through a table containing all 20 columns. After Vertical Partitioning:
The table is split into two:- Profile_Basic: Contains columns
UserID,Name,Email. - Profile_Details: Contains columns
UserID,Preferences,Activity Logs,Profile Settings.
Now, a query that only requires basic profile information accesses the smaller Profile_Basic table, improving performance and reducing I/O load.
- Profile_Basic: Contains columns
Advantages
- Improved Query Performance:
- Queries that only need a subset of columns can access a smaller table, reducing the amount of data read from disk and speeding up retrieval.
- Reduced I/O and Memory Usage:
- By isolating frequently used columns, the system can optimize caching and memory utilization, leading to faster processing times.
- Better Security and Compliance:
- Sensitive data can be isolated in a separate partition with more stringent access controls, helping meet regulatory requirements.
- Easier Maintenance:
- Smaller tables can be easier to manage, update, and backup. They also reduce the impact of schema changes since fewer columns are affected at a time.
Disadvantages:
- Increased Query Complexity:
When data is spread across multiple tables, queries that need to retrieve columns from different partitions must perform join operations. These joins can add complexity and sometimes impact performance if not optimized properly. - Maintenance Overhead:
Managing multiple tables instead of one increases the complexity of database administration. Schema changes, backup procedures, and data consistency checks must be carefully coordinated across all partitions. - Potential Performance Impact:
Although vertical partitioning improves performance for queries targeting specific columns, queries that require data from multiple partitions might suffer from the overhead of performing joins, potentially negating some of the benefits. - Data Consistency Challenges:
Ensuring consistency across partitions can be more challenging. Any inconsistency in how data is distributed or updated between partitions may lead to errors or require additional mechanisms to maintain integrity. - Increased Complexity in Application Logic:
Applications may need to be aware of the partitioning strategy to efficiently retrieve data, which can increase development complexity and require more advanced query planning.
Data Partitioning Criteria
It is the set of rules or guidelines used to decide how to divide data in a database. These criteria help ensure that the partitioning strategy aligns with performance, scalability, and maintenance goals.
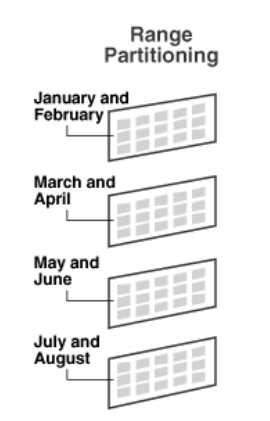
1️⃣ Range Based Partitioning
In range partitioning, data is divided into segments based on specific value ranges of the partition key. Each partition is assigned a contiguous, non-overlapping range defined by a lower and upper bound. Values that meet or exceed the upper bound of a given range are placed in the subsequent partition.
For example, range partitioning is particularly useful when organizing data by date and time. A table with a date column as its partition key might have a partition for January 2022 that includes all rows with dates from January 1 to January 31, 2022.
Another common use case is when data is continuously added and there is a need to efficiently remove outdated records. Partitioning data into date ranges makes it easier to delete old data. For instance, rather than executing a delete query on a massive table to remove employee records dated before 1991, one can simply drop the partition containing data for employees who left before that year.
- Ranges should be contiguous but not overlapping, where each range specifies a non-inclusive lower and upper bound of partition.
- Any partitioning key values equal to or higher than the upper bound of the range are added to the next partition.
Advantages:
- Simple to implement
Disadvantages:
- Uneven distribution if data is skewed (e.g., some ranges have more users).
2️⃣ Hash-Based Partitioning
In hash partitioning, rows are allocated to different partitions using a hashing algorithm, rather than grouping by continuous ranges as in range partitioning.
For example:
- A client's IP address or an application ID can be input into a hash function to generate a hash value, which then determines the appropriate partition. If there are 4 database partitions, you might use a modulo operation on the application ID (application ID % 4) to decide which partition to use.
- This method effectively distributes data evenly across partitions.
- Hash partitioning is particularly useful when the data does not have a natural or historical partition key, making it an easy alternative to range partitioning.
HASH(user_id) % number_of_shards // determines the shard.Advantage:
- Distributes data more evenly than range-based.
Disadvantage:
It becomes costly to add or remove database servers dynamically. For instance, increasing the number of partitions may require remapping keys and migrating data to new partitions, which can involve modifying the hash function. During such migrations, many requests may go unserved, potentially leading to downtime. This issue can be mitigated by using consistent hashing.
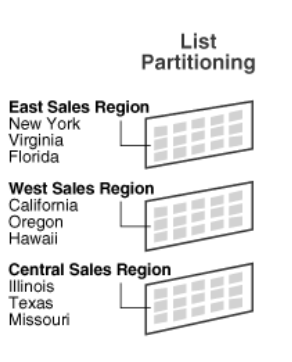
3️⃣ List Based Partitioning
List partitioning assigns rows to partitions based on specific lists of values for a given column, rather than using contiguous ranges. Here are the main points:
- The partition key is restricted to a single column.
- It enables the grouping of unrelated data sets into distinct partitions.
- For example, you can partition data by region so that all records from a particular region, such as India, reside in one partition while records from other regions are stored separately.
Consider a table containing data for 20 video stores across four regions:
- India: ID Numbers 3, 5, 6, 9, 17
- USA: ID Numbers 1, 2, 10, 11, 19, 20
- Japan: ID Numbers 4, 12, 13, 14, 18
- UK: ID Numbers 7, 8, 15, 16
Using list partitioning, each region’s data is placed in its own partition. This makes it straightforward to add or remove records for a particular region without affecting the others.
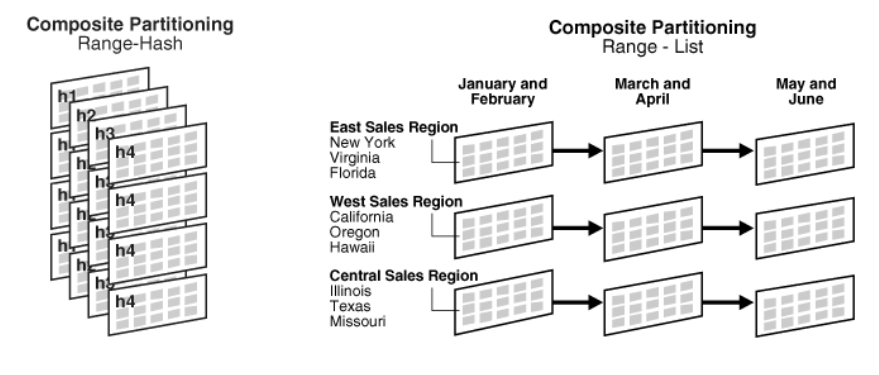
4️⃣ Composite Partitioning
Composite partitioning is a strategy that uses two or more partitioning techniques to organize data efficiently. The process starts by dividing the data using one method, and then further splitting each partition into sub-partitions using the same or a different technique. Together, these sub-partitions form a logical subset of the overall data.
This method is particularly useful for managing large datasets because it allows for precise control over where and how data is stored, ultimately enhancing both performance and scalability.
There are several types of composite partitioning:
- Composite Range-Range Partitioning:
Data is initially divided based on a range of values (for example, by date) and then further segmented using another range criteria (such as price). - Composite Range-Hash Partitioning:
The first step is to partition data by range, and each resulting partition is then subdivided using a hash function. - Composite Range-List Partitioning:
After the initial range partitioning, each partition is further divided using list partitioning, allowing categorization by a specific set of values. - Composite List-Range Partitioning:
Data is first partitioned based on a list (such as by country name), and then each list partition is further segmented by a range (for example, by date). - Composite List-Hash Partitioning:
Following an initial list partitioning, each partition is further broken down using a hash partitioning method. - Composite List-List Partitioning:
This approach applies list partitioning on two levels, such as partitioning first by country name and then sub-partitioning by customer account status.

Leave a comment
Your email address will not be published. Required fields are marked *