
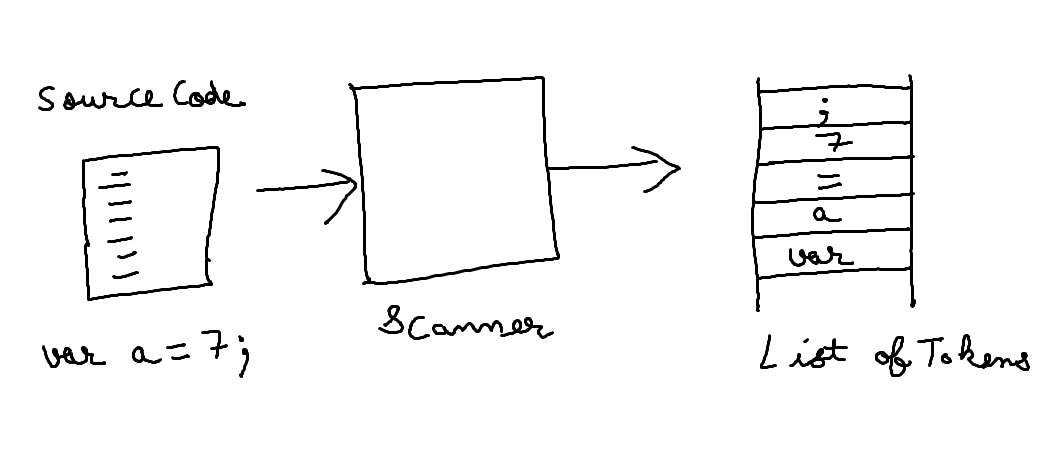
The first step in any compiler or interpreter is scanning. The scanner takes in raw source code as a series of characters and groups it into a series of chunks we call tokens. These are the meaningful “words” and “punctuation” that make up the language’s grammar.
This task also called “Scanning” and “lexing” (short for “lexical analysis”).
The first task we need to do is to create the main function that accepts the file path as a command line argument. Visit the below link to get idea of how to create a simple program that accepts the command line arguments:
#1 Argument Parsing
Argument parsing is the process of extracting command-line arguments provided to a program and using them to control its behavior. Command-line arguments can include options, flags, and parameters that determine how the program operates. Proper argument parsing is essential for user-friendly command-line interfaces and robust program functionality.
#1.1 Creating a Command-Line Program in C/C++:
Step 1: Include Necessary Headers:
#include <iostream>
#include <string>
Step 2: Define the Main Function:
int main(int argc, char* argv[]) {
// Argument parsing logic will be implemented here
return 0;
}
Step 3: Check Argument Count:
If argument count is less than 2 (i.e 1), means file path is not supplied.
In C and C++, when a program is executed from the command line without any additional arguments, the first argument (argv[0]) always holds the name of the program itself. Therefore, the argument count (argc) will be at least 1.
if (argc < 2) {
std::cerr << "Usage: " << argv[0] << " <file_path>" << std::endl;
return 1; // Exit with error code 1
}
Step 4: Retrieving the File Path:
Assuming the user has provided the file path, we proceed to extract this essential piece of information from the command-line arguments.
std::string filePath = argv[1];
Step 5: For the time being Just Print the File Path:
// Print the provided file path
std::cout << "File path provided: " << filePath << std::endl;
// Implement further logic to operate on the provided file
Complete Program:
// Include necessary headers
#include <iostream>
#include <string>
int main(int argc, char* argv[]) {
// Check if at least one command-line argument (file path) is provided
if (argc < 2) {
std::cerr << "Usage: " << argv[0] << " <file_path>" << std::endl;
return 1; // Exit with error code 1
}
// Retrieve the file path from the command-line arguments
std::string filePath = argv[1];
// Print the provided file path
std::cout << "File path provided: " << filePath << std::endl;
// You can now use 'filePath' in your program to operate on the provided file
return 0; // Exit with success
}
#2 File Reader
Our Interpreter(FarmScript) will support two ways of running code. If you start FarmScript from the command line and give it a path to a file, it reads the file and executes it.
If you want a more intimate conversation with your interpreter, you can also run it interactively. Fire up FarmScript interpreter without any arguments, and it drops you into a prompt where you can enter and execute code one line at a time.
An interactive prompt is also called a “REPL” (pronounced like “rebel” but with a “p”). The name comes from Lisp where implementing one is as simple as wrapping a loop around a few built-in functions:
(print (eval (read)))
Working outwards from the most nested call, you Read a line of input, Evaluate it, Print the result, then Loop and do it all over again.
void runFile(const std::string& filePath) {
std::ifstream file(filePath);
if (!file.is_open()) {
std::cerr << "Error: Could not open file '" << filePath << "'"
<< std::endl;
std::exit(1);
}
std::stringstream buffer;
buffer << file.rdbuf();
std::string source = buffer.str();
run(source);
file.close();
}void runPrompt() {
std::string line;
while (true) {
std::cout << "> ";
if (!std::getline(std::cin, line) || line == "exit") break;
run(line);
}
}Both the prompt and the file runner are thin wrappers around this core function:
void run(const std::string& source) {
// Implement interpreter logic here
std::cout << "Running code: " << source << std::endl;
}It is not doing much for the time being just printing the file or REPL data.
#3 Error Handling
Error handling is a critical aspect of any language implementation, as it significantly impacts the usability and user experience of the language. While textbooks may sometimes overlook error handling in favor of more formal computer science topics, in practice, gracefully handling errors is vital for creating a usable language.
When users encounter errors in their code, the tools provided by the language to handle those errors play a crucial role in guiding users back to a successful execution path. Error messages should provide users with all the necessary information to understand what went wrong and help them navigate back to their intended goal.
In the context of our interpreter, we'll start by implementing basic error reporting functionality. The error() function, along with its helper report() function, will notify users of syntax errors occurring on specific lines. While this implementation may seem minimal, it's a fundamental starting point for error reporting. For instance, if a user accidentally leaves a dangling comma in a function call, our interpreter will print an error message indicating the line number where the error occurred.
Although more detailed error messages, such as pointing out the exact location of the error within the line, would be beneficial to users, implementing such functionality involves complex string manipulation code, which we'll omit for simplicity's sake.
The hadError field, declared in the FarmScript class, ensures that we don't attempt to execute code with known errors. Additionally, it allows us to exit the program with a non-zero exit code, as appropriate for command-line applications.
To maintain a consistent error-handling approach, error reporting is centralized in the FarmScript class. We reset the hadError flag in the interactive loop to prevent a single mistake from terminating the user's entire session.
// Inside runPrompt() method
run(line);
hadError = false;
The other reason I pulled the error reporting out here instead of stuffing it into the scanner and other phases where the error might occur is to remind you that it’s good engineering practice to separate the code that generates the errors from the code that reports them.
Various phases of the front end will detect errors, but it’s not really their job to know how to present that to a user. In a full-featured language implementation, you will likely have multiple ways errors get displayed: on stderr, in an IDE’s error window, logged to a file, etc. You don’t want that code smeared all over your scanner and parser.
Ideally, we would have an actual abstraction, some kind of “ErrorReporter” interface that gets passed to the scanner and parser so that we can swap out different reporting strategies. For our simple interpreter here, I didn’t do that, but I did at least move the code for error reporting into a different class.
Complete Code
#include <fstream>
#include <iostream>
#include <sstream>
#include <string>
class FarmScript {
public:
void runFile(const std::string& filePath) {
std::ifstream file(filePath);
if (!file.is_open()) {
std::cerr << "Error: Could not open file '" << filePath << "'"
<< std::endl;
std::exit(1);
}
std::stringstream buffer;
buffer << file.rdbuf();
std::string source = buffer.str();
run(source);
file.close();
}
void runPrompt() {
std::string line;
while (true) {
std::cout << "> ";
if (!std::getline(std::cin, line) || line == "exit") break;
run(line);
}
}
void run(const std::string& source) {
// Implement interpreter logic here
std::cout << "Running code: " << source << std::endl;
}
};
int main(int argc, char* argv[]) {
FarmScript interpreter;
if (argc > 2) {
std::cerr << "Usage: jlox [script]" << std::endl;
std::exit(64);
} else if (argc == 2) {
interpreter.runFile(argv[1]);
} else {
interpreter.runPrompt();
}
return 0;
}#4 Tokens
A token is a data structure that represents a lexeme along with its associated type and any additional information, such as the literal value of the lexeme (if applicable).
class Token
{
public:
TokenType type;
std::string lexeme;
Object literal;
int line;
Token(TokenType type_, std::string lexeme_, Object *literal_, int line_);
std::string str();
};A token typically consists of the following components:
#4.1. Token Type
Represents the category or type of the lexeme, such as keywords, identifiers, literals, punctuation etc.
Tokens can be categorized into different types, such as:
- Keywords: Reserved words that have special meaning in the language and cannot be used for other purposes. Examples include if, else, for, while, etc.
- Identifiers: Names given to variables, functions, classes, or any other user-defined entities in the program. Identifiers usually consist of letters, digits, and underscores, and they must follow certain rules defined by the language.
- Literals: Representations of constant values, such as numbers, characters, or strings. For example, 42 is an integer literal, 'a' is a character literal, and "hello" is a string literal.
- Operators: Symbols used to perform operations on operands. Examples include arithmetic operators (+, -, *, /), comparison operators (==, !=, <, >), logical operators (&&, ||, !), etc.
- Punctuation: Symbols used for syntactic purposes, such as grouping expressions (
(, )), separating statements (;), defining blocks of code ({, }), etc. - Comments: Text ignored by the compiler or interpreter, used for documenting the code or adding notes. Comments are not considered part of the executable code. They can be single-line (//) or multi-line (/* ... */).
- Whitespace: Spaces, tabs, newlines, and other characters used for formatting the code. Whitespace is usually ignored by the compiler or interpreter but is necessary for human readability.
#ifndef TOKEN_TYPE_H
#define TOKEN_TYPE_H
// Enumeration representing token types
enum class TokenType {
// Single-character tokens
LEFT_PAREN, RIGHT_PAREN, LEFT_BRACE, RIGHT_BRACE,
COMMA, DOT, MINUS, PLUS, SEMICOLON, SLASH, STAR,
// One or two character tokens
BANG, BANG_EQUAL,
EQUAL, EQUAL_EQUAL,
GREATER, GREATER_EQUAL,
LESS, LESS_EQUAL,
// Literals
IDENTIFIER, STRING, NUMBER,
// Keywords
AND, CLASS, ELSE, FALSE, FUN, FOR, IF, NIL, OR,
PRINT, RETURN, SUPER, THIS, TRUE, VAR, WHILE,
EOF
};
#endif // TOKEN_TYPE_HDuring the lexical analysis phase of compilation or interpretation, the source code is broken down into tokens. These tokens are then passed to the parser, which constructs a syntax tree or other intermediate representation of the program based on the rules defined by the language's grammar.
var x = 10;The tokens in this line of code are:
Keywordtoken: Represents the lexemevar.Identifiertoken: Represents the lexemex.Assignment operatortoken: Represents the lexeme=.Integer Literaltoken: Represents the lexeme10.Semicolontoken: Represents the lexeme;.
A token contains a lot of information like token type, lexeme, literal, which line.
class Token
{
public:
TokenType type;
std::string lexeme;
Object literal;
int line;
Token(TokenType type_, std::string lexeme_, Object *literal_, int line_);
std::string str();
};
std::ostream &operator<<(std::ostream &os, Token &t);
#endif // _TOKEN_H#4.2 Lexemes
Lexemes are like the actual words in a sentence. They're the individual characters or sequences of characters in your code that have meaning. They're like the bricks that build up your code.
Example:
var x = 10;The lexemes in this line of code are:
varx=10;
#4.3 Literal value
There are lexemes for literal values—numbers and strings and the like. Since the scanner has to walk each character in the literal to correctly identify it, it can also convert that textual representation of a value to the living runtime object that will be used by the interpreter later.
Object literal;#4.4 Location information
Back when I was preaching the gospel about error handling, we saw that we need to tell users where errors occurred. Tracking that starts here. In our simple interpreter, we note only which line the token appears on, but more sophisticated implementations include the column and length too.
Some token implementations store the location as two numbers: the offset from the beginning of the source file to the beginning of the lexeme, and the length of the lexeme. The scanner needs to know these anyway, so there’s no overhead to calculate them.
An offset can be converted to line and column positions later by looking back at the source file and counting the preceding newlines. That sounds slow, and it is. However, you need to do it only when you need to actually display a line and column to the user. Most tokens never appear in an error message. For those, the less time you spend calculating position information ahead of time, the better.
int line;#5 Regular Languages and Expressions
Now that we know what we’re trying to produce, let’s, well, produce it. The core of the scanner is a loop. Starting at the first character of the source code, the scanner figures out what lexeme the character belongs to, and consumes it and any following characters that are part of that lexeme. When it reaches the end of that lexeme, it emits a token.
Then it loops back and does it again, starting from the very next character in the source code. It keeps doing that, eating characters and occasionally, uh, excreting tokens, until it reaches the end of the input.
The part of the loop where we look at a handful of characters to figure out which kind of lexeme it “matches” may sound familiar. If you know regular expressions, you might consider defining a regex for each kind of lexeme and using those to match characters. For example, FarmScript has the same rules as C for identifiers (variable names and the like). This regex matches one:
[a-zA-Z_][a-zA-Z_0-9]*
If you did think of regular expressions, your intuition is a deep one. The rules that determine how a particular language groups characters into lexemes are called its lexical grammar. In FarmScript, as in most programming languages, the rules of that grammar are simple enough for the language to be classified a regular language. That’s the same “regular” as in regular expressions.
You very precisely can recognize all of the different lexemes for Lox using regexes if you want to, and there’s a pile of interesting theory underlying why that is and what it means. Tools like Lex or Flex are designed expressly to let you do this—throw a handful of regexes at them, and they give you a complete scanner back.
Since our goal is to understand how a scanner does what it does, we won’t be delegating that task. We’re about handcrafted goods.
#6 The Scanner Class
Without further ado, let's make ourselves a scanner.
#ifndef _SCANNER_H
#define _SCANNER_H
#include <string>
#include <vector>
#include "Token.h"
class Scanner
{
private:
unsigned int start = 0;
unsigned int current = 0;
unsigned int line = 1;
std::string source;
std::vector<Token> tokens;
public:
Scanner(std::string source_);
std::vector<Token> scanTokens();
private:
bool isAtEnd();
void scanToken();
char advance();
void addToken(TokenType type);
void addString(std::string str);
void addNumber(double num);
bool match(char expected);
char peek();
char peekNext();
void string();
bool isDigit(char c);
bool isAlpha(char c);
bool isAlphaNum(char c);
void number();
void identifier();
void blockComment();
};
#endif //_SCANNER_H#include <unordered_map>
#include <FarmScript.h>
#include <Scanner.h>
Scanner::Scanner(std::string source_)
{
source = source_;
}
std::vector<Token> Scanner::scanTokens()
{
while (!isAtEnd())
{
start = current;
scanToken();
}
Object nil;
Token eofToken(EOF_TOKEN, "", &nil, line);
tokens.push_back(eofToken);
return tokens;
}
bool Scanner::isAtEnd()
{
return current >= source.length();
}
void Scanner::scanToken()
{
char c = advance();
switch (c)
{
case '(': addToken(LEFT_PAREN); break;
case ')': addToken(RIGHT_PAREN); break;
case '{': addToken(LEFT_BRACE); break;
case '}': addToken(RIGHT_BRACE); break;
case ',': addToken(COMMA); break;
case '?': addToken(QUESTION); break;
case ':': addToken(COLON); break;
case '.': addToken(DOT); break;
case '-': addToken(MINUS); break;
case '+': addToken(PLUS); break;
case ';': addToken(SEMICOLON); break;
case '/':
if (match('/'))
{
while ((peek() != '\n') && !isAtEnd())
{
advance();
}
}
else if (match('*'))
{
blockComment();
}
else
{
addToken(SLASH);
}
break;
case '*': addToken(STAR); break;
case '!': addToken(match('=') ? BANG_EQUAL : BANG); break;
case '=': addToken(match('=') ? EQUAL_EQUAL : EQUAL); break;
case '>': addToken(match('=') ? GREATER_EQUAL : GREATER); break;
case '<': addToken(match('=') ? LESS_EQUAL : LESS); break;
case ' ':
case '\r':
case '\t':
break;
case '\n':
line++;
break;
case '"':
string();
break;
default:
if (isDigit(c))
{
number();
}
else if (isAlpha(c))
{
identifier();
}
else
{
FarmScript::error(line, "Invalid character");
}
break;
}
}
char Scanner::advance()
{
return source[current++];
}
void Scanner::addToken(TokenType type)
{
std::string substr = source.substr(start, current - start);
Object nil;
Token token(type, substr, &nil, line);
tokens.push_back(token);
}
bool Scanner::match(char expected)
{
if (isAtEnd())
{
return false;
}
else if (source[current] != expected)
{
return false;
}
current++;
return true;
}
char Scanner::peek()
{
if (isAtEnd())
{
return '\0';
}
return source[current];
}
char Scanner::peekNext()
{
if ((current + 1) >= source.length())
{
return '\0';
}
return source[current + 1];
}
void Scanner::addString(std::string str)
{
std::string substr = source.substr(start, current - start);
Object objStr(str);
Token token(STRING, substr, &objStr, line);
tokens.push_back(token);
}
void Scanner::addNumber(double num)
{
std::string substr = source.substr(start, current - start);
Object objNum(num);
Token token(NUMBER, substr, &objNum, line);
tokens.push_back(token);
}
void Scanner::string()
{
while ((peek() != '"') && !isAtEnd())
{
if (peek() == '\n')
{
line++;
}
advance();
}
if (isAtEnd())
{
FarmScript::error(line, "Unterminated string");
return;
}
advance(); // closing "
// remove enclosing ""
std::string str = source.substr(start + 1, current - start - 2);
addString(str);
}
bool Scanner::isDigit(char c)
{
return (c >= '0') && (c <= '9');
}
bool Scanner::isAlpha(char c)
{
return ((c >= 'a') && (c <= 'z')) || ((c >= 'A') && (c <= 'Z')) || (c == '_');
}
bool Scanner::isAlphaNum(char c)
{
return isDigit(c) || isAlpha(c);
}
void Scanner::number()
{
while (isDigit(peek()))
{
advance();
}
if ((peek() == '.') && isDigit(peekNext()))
{
advance();
while (isDigit(peek()))
{
advance();
}
}
std::string str = source.substr(start, current - start);
double num = stod(str);
addNumber(num);
}
static std::unordered_map<std::string, TokenType> keywords({
{ "and", AND },
{ "class", CLASS },
{ "else", ELSE },
{ "false", FALSE_TOKEN },
{ "for", FOR },
{ "fun", FUN },
{ "if", IF },
{ "nil", NIL },
{ "or", OR },
{ "print", PRINT },
{ "return", RETURN },
{ "super", SUPER },
{ "this", THIS },
{ "true", TRUE_TOKEN },
{ "var", VAR },
{ "while", WHILE },
{ "break", BREAK},
});
void Scanner::identifier()
{
while (isAlphaNum(peek()))
{
advance();
}
TokenType type;
std::string str = source.substr(start, current - start);
auto it = keywords.find(str);
if (it != keywords.end())
{
type = it->second;
}
else
{
type = IDENTIFIER;
}
addToken(type);
}
void Scanner::blockComment()
{
while (!isAtEnd())
{
if (peek() == '\n')
{
line++;
advance();
}
else if ((peek() == '/') && (peekNext() == '*'))
{
advance();
advance();
blockComment(); // nested comment
}
else if ((peek() == '*') && (peekNext() == '/'))
{
advance();
advance();
return;
}
else
{
advance();
}
}
FarmScript::error(line, "Unterminated comment");
}
We store the raw source code as a simple string, and we have a list ready to fill with tokens we’re going to generate. The aforementioned loop that does that looks like this:
std::vector<Token> Scanner::scanTokens() {
while (!isAtEnd()) {
// We are at the beginning of the next lexeme.
start = current;
scanToken();
}
Object nil;
Token eofToken(EOF_TOKEN, "", &nil, line);
tokens.push_back(eofToken);
return tokens;
}
The scanner works its way through the source code, adding tokens until it runs out of characters. Then it appends one final "EOF_TOKEN” token, which indicates the end of the file. That isn't strictly needed, but it makes our parser a little cleaner.
This loop depends on a couple of fields to keep track of where the scanner is in the source code.
int start = 0;
int current = 0;
int line = 1;The start and current fields are offsets that index into the string. The start field points to the first character in the lexeme being scanned, and current points at the character currently being considered. The line field tracks what source line current is on so we can produce tokens that know their location.
Then we have one little helper function that tells us if we’ve consumed all the characters.
boolean isAtEnd() {
return current >= source.length();
}#6.1 Recognizing Lexemes
In each turn of the loop, we scan a single token. This is the real heart of the scanner. We’ll start simple. Imagine if every lexeme were only a single character long. All you would need to do is consume the next character and pick a token type for it. Several lexemes are only a single character in FarmScript, so let’s start with those.
void Scanner::scanToken()
{
char c = advance();
switch (c)
{
case '(': addToken(LEFT_PAREN); break;
case ')': addToken(RIGHT_PAREN); break;
case '{': addToken(LEFT_BRACE); break;
case '}': addToken(RIGHT_BRACE); break;
case ',': addToken(COMMA); break;
case '?': addToken(QUESTION); break;
case ':': addToken(COLON); break;
case '.': addToken(DOT); break;
case '-': addToken(MINUS); break;
case '+': addToken(PLUS); break;
case ';': addToken(SEMICOLON); break;
case '/':
if (match('/'))
{
while ((peek() != '\n') && !isAtEnd())
{
advance();
}
}
else if (match('*'))
{
blockComment();
}
else
{
addToken(SLASH);
}
break;
case '*': addToken(STAR); break;
case '!': addToken(match('=') ? BANG_EQUAL : BANG); break;
case '=': addToken(match('=') ? EQUAL_EQUAL : EQUAL); break;
case '>': addToken(match('=') ? GREATER_EQUAL : GREATER); break;
case '<': addToken(match('=') ? LESS_EQUAL : LESS); break;
case ' ':
case '\r':
case '\t':
break;
case '\n':
line++;
break;
case '"':
string();
break;
default:
if (isDigit(c))
{
number();
}
else if (isAlpha(c))
{
identifier();
}
else
{
FarmScript::error(line, "Invalid character");
}
break;
}
}advance():
char Scanner::advance() {
return source[current++];
}- This function retrieves the character at the
currentposition in the source code and then increments thecurrentindex. It returns the character that was retrieved. Initially current is0which points to character in source at 0th index.source= This is the source codestd::string source;
#6.1.1 Handling the Single-character Tokens:
For the single-character tokens, This scanToken just calls the addToken(TokenType) with corresponding TokenType. For example:
If character is (, then calls addToken(LEFT_PAREN).
case '(': addToken(LEFT_PAREN); break;
case ')': addToken(RIGHT_PAREN); break;
case '{': addToken(LEFT_BRACE); break;
case '}': addToken(RIGHT_BRACE); break;
case ',': addToken(COMMA); break;
case '?': addToken(QUESTION); break;
case ':': addToken(COLON); break;
case '.': addToken(DOT); break;
case '-': addToken(MINUS); break;
case '+': addToken(PLUS); break;
case ';': addToken(SEMICOLON); break;
case '*': addToken(STAR); break;void Scanner::addToken(TokenType type)
{
// lexeme
std::string substr = source.substr(start, current - start);
Object nil;
Token token(type, substr, &nil, line);
tokens.push_back(token);
}
The advance() method consumes the next character in the source file and returns it. Where advance() is for input, addToken() is for output. It grabs the text of the current lexeme and creates a new token for it.
addToken(TokenType): It is responsible for adding a token to vector of tokens.std::string substr = source.substr(start, current - start);= This line
#6.1.2 Handling comments and whitespaces:
This part handles comments and whitespaces characters. It skips over single-line comments by advancing until it reaches a newline character. It also handles comments (/* */) by calling a function
#6.1.3 Handling newline characters:
case '\n':
line++;
break;It increments the line counter when encountering a newline character, which helps to keep track of the current line number in the source code.
#6.1.4 Handling strings, number, identifiers, and errors
case '"':
string();
break;
default:
if (isDigit(c))
{
number();
}
else if (isAlpha(c))
{
identifier();
}
else
{
FarmScript::error(line, "Invalid character");
}
break;This part handles strings (enclosed in quotes (")), numbers, and identifiers (variable names, keywords).
1) Handle strings:
case '"':
string();
break;void Scanner::string() {
// Scan characters until the closing double quote is encountered or until the end of the source code
while ((peek() != '"') && !isAtEnd()) {
// If a newline character is encountered, increment the line number
if (peek() == '\n') {
line++;
}
// Move to the next character
advance();
}
// Check if the string is unterminated (if we reached the end of the source code before finding the closing double quote)
if (isAtEnd()) {
FarmScript::error(line, "Unterminated string");
return; // Return early if the string is unterminated
}
// Move past the closing double quote
advance();
// Extract the substring representing the string literal (excluding the enclosing double quotes)
std::string str = source.substr(start + 1, current - start - 2);
// Add the string literal token to the token list
addString(str);
}
string():
Let's break this function:
// Scan characters until the closing double quote is encountered or until the end of the source code
while ((peek() != '"') && !isAtEnd()) {
// If a newline character is encountered, increment the line number
if (peek() == '\n') {
line++;
}
// Move to the next character
advance();
}Scan characters until the closing double quote is encountered or until the end of the source code:
- The
whileloop iterates through characters in the source code until it finds the closing double quote (") or until it reaches the end of the source code. - If a newline character (
\n) is encountered within the string literal, the line number is incremented.
// Check if the string is unterminated (if we reached the end of the source code before finding the closing double quote)
if (isAtEnd()) {
FarmScript::error(line, "Unterminated string");
return; // Return early if the string is unterminated
}Check if string is unterminated:
- After the loop, if we've reached the end of the source code without finding the closing double quote, it means the string is unterminated.
- In this case, an error is reported using the
FarmScript::errorfunction with the current line number, and the function returns early.
// Move past the closing double quote
advance();Move next to the closing double quote:
- Once the closing double quote is found, the scanner advances past it to move to the next character.
// Extract the substring representing the string literal (excluding the enclosing double quotes)
std::string str = source.substr(start + 1, current - start - 2);
Extract the substring representing the string literal (excluding the enclosing double quotes):
- The function extracts the substring from the source code that represents the string literal, excluding the enclosing double quotes.
- This substring is then stored in the
strvariable.
// Add the string literal token to the token list
addString(str);void Scanner::addString(std::string str)
{
//lexeme "string"
std::string substr = source.substr(start, current - start);
Object objStr(str);
Token token(STRING, substr, &objStr, line);
tokens.push_back(token);
}Add the string literal token to the token list:
- Finally, the function call
addStringto add the string literal to the token list.
2) Handling numbers
default:
if (isDigit(c))
{
number();
}
else if (isAlpha(c))
{
identifier();
}
else
{
FarmScript::error(line, "Invalid character");
}
break;It calls respective function (number, identifier, and error) to handle all these cases.
isDigit(.):
bool Scanner::isDigit(char c)
{
return (c >= '0') && (c <= '9');
}This function checks whether a given character c represents a digit (0-9) or not.
If true that is the number is digit, it calls number() function:
number():
void Scanner::number()
{
// Scan digits before decimal point
while (isDigit(peek()))
{
advance();
}
// Check for decimal point and scan digit after it
if ((peek() == '.') && isDigit(peekNext()))
{
advance();
while (isDigit(peek()))
{
advance();
}
}
std::string str = source.substr(start, current - start);
double num = stod(str);
addNumber(num);
}char Scanner::peek() {
if (isAtEnd()) {
return '\0'; // Return null character if at the end of the source code
}
return source[current]; // Return the next character in the source code
}
peek():
- The
ifstatement checks if the scanner has reached the end of the source code. This is determined by theisAtEnd()function, which checks if the current position (current) is beyond the length of the source code. - If the end of the source code is reached, the function returns the null character (
\0). This signifies that there are no more characters to peek at. - If the end of the source code has not been reached, the function returns the character at the current position (
current) in the source code. - This character represents the next character in the source code that scanner has not yet processed. As we already seen that current has been incremented already in the
advancefunction in thescanTokenparent function.source[current++];
Let's break the number():
Scanning Digits before the decimal point
// Scan digits before decimal point
while (isDigit(peek()))
{
advance();
}- The
whileloop iterates through consecutive digits (0-9) in the source code until a non-digit character is encountered.advance()function returns the char at current position if needed and increments the current position.
Checking for a decimal point and scanning digits after it:
// Check for decimal point and scan digits after it
if ((peek() == '.') && isDigit(peekNext())) {
advance(); // Consume the decimal point by incrementing the current
// Scan digits after decimal point
while (isDigit(peek())) {
advance();
}
}- After scanning the integral part of the numeric literal, the function checks if the next character is a decimal point (
.). - If a decimal point is found and the character following it is a digit, it means there is a fractional part to the numeric literal.
- In this case, another
whileloop is used to scan the digits after the decimal point.
Extracting the substring representing the numeric literal:
// Extract the substring representing the numeric literal
std::string str = source.substr(start, current - start);- Extract the complete literal (both integral and fractional parts) is scanned, the function extracts the substring from the source code that represents the entire numeric literal.
- This substring is then stored in the
strvariable.
Converting the string to a double:
// Convert the string to a double
double num = stod(str);- The string representing the numeric literal is converted to a
doubleusing thestod(string to double) function. - This converts the textual representation of the number into its floating-point equivalent.
Adding the numeric literal token to the token list:
// Add the numeric literal token to the token list
addNumber(num);void Scanner::addNumber(double num)
{
std::string substr = source.substr(start, current - start);
Object objNum(num);
Token token(NUMBER, substr, &objNum, line);
tokens.push_back(token);
}- Finally, the function calls
addNumberto add the numeric literal token (of typeNUMBER) to the token list.
3) Handle identifiers:
else if (isAlpha(c))
{
identifier();
}- If character is alpha then calls the
identifier()method.
isAlpha(char):
bool Scanner::isAlpha(char c)
{
return ((c >= 'a') && (c <= 'z')) || ((c >= 'A') && (c <= 'Z')) || (c == '_');
}- It checks whether a given character
cis an alphabetic character (either uppercase or lowercase) or an underscore (_).
identifier();:
void Scanner::identifier() {
// Scan characters while they are alphanumeric or underscores
while (isAlphaNum(peek())) {
advance();
}
// Determine the token type for the identifier
TokenType type;
std::string str = source.substr(start, current - start);
auto it = keywords.find(str);
if (it != keywords.end()) {
type = it->second; // If the identifier is a keyword, set the token type accordingly
} else {
type = IDENTIFIER; // Otherwise, it's a regular identifier
}
// Add the token to the token list
addToken(type);
}
Let's break it up:
Scanning character for the identifiers:
// Scan characters while they are alphanumeric or underscores
while (isAlphaNum(peek())) {
advance();
}bool Scanner::isAlphaNum(char c)
{
return isDigit(c) || isAlpha(c);
}Scanning characters for the identifier:
- The
whileloop iterates through consecutive characters in the source code while they are alphanumeric or underscores. It uses theisAlphaNumfunction to determine if the current character is alphanumeric (a letter or a digit) or an underscore. peek()function returns the character pointed by current.advance()function returns the character pointed by current which we don't need and increments the current.
// Determine the token type for the identifier
TokenType type;
std::string str = source.substr(start, current - start);
auto it = keywords.find(str);
if (it != keywords.end()) {
type = it->second; // If the identifier is a keyword, set the token type accordingly
} else {
type = IDENTIFIER; // Otherwise, it's a regular identifier
}
Determining the token type for the identifier
- After scanning the identifier, the function extracts the substring representing the identifier from the source code using
substr(start, current - start). - It then looks up this substring in a map named
keywords. If then substring matches a key map, it means the identifier is a keyword in the programming language, so the corresponding token type is retrieved from the map. - If the substring doesn't match any keyword, it means the identifier is a regular identifier, so the token type is set to
IDENTIFIER.
// Add the token to the token list
addToken(type);Adding the token to the token list:
- Finally, the function calls
addTokento add the token with the determined token type to the token list.
4) Handle errors:
else
{
FarmScript::error(line, "Invalid character");
}
break;Handle invalid character:
- If the character is neither a digit nor an alphabetic character, it is considered an invalid character.
- The
FarmScript::errorfunction is called to report an error, passing the current line (line) and a message indicating the presence of an invalid character.
#6.2 Lexical errors
Before we get too far in, let’s take a moment to think about errors at the lexical level. What happens if a user throws a source file containing some characters Lox doesn’t use, like @#^, at our interpreter? Right now, those characters get silently discarded. They aren’t used by the Lox language, but that doesn’t mean the interpreter can pretend they aren’t there. Instead, we report an error.
case '*': addToken(STAR); break;
default:
FarmScript.error(line, "Unexpected character.");
break;
}Note that the erroneous character is still consumed by the earlier call to advance(). That’s important so that we don’t get stuck in an infinite loop.
Note also that we keep scanning. There may be other errors later in the program. It gives our users a better experience if we detect as many of those as possible in one go. Otherwise, they see one tiny error and fix it, only to have the next error appear, and so on. Syntax error Whac-A-Mole is no fun.
Note: Don’t worry. Since hadError gets set, we’ll never try to execute any of the code, even though we keep going and scan the rest of it.
#6.3 Operators
We have single-character lexemes working, but that doesn’t cover all of FarmScript’s operators. What about !? It’s a single character, right? Sometimes, yes, but if the very next character is an equals sign, then we should instead create a != lexeme. Note that the ! and = are not two independent operators. You can’t write ! = in FarmScript and have it behave like an inequality operator. That’s why we need to scan != as a single lexeme. Likewise, <, >, and = can all be followed by = to create the other equality and comparison operators.
For all of these, we need to look at the second character.
case '!':
addToken(match('=') ? BANG_EQUAL : BANG);
break;
case '=':
addToken(match('=') ? EQUAL_EQUAL : EQUAL);
break;
case '<':
addToken(match('=') ? LESS_EQUAL : LESS);
break;
case '>':
addToken(match('=') ? GREATER_EQUAL : GREATER);
break;
Those cases use this new method:
bool Scanner::match(char expected) {
if (isAtEnd()) {
return false; // Return false if we have reached the end of the source code
} else if (source[current] != expected) {
return false; // Return false if the current character does not match the expected character
}
current++; // Move to the next character
return true; // Return true indicating a successful match
}
It's like a conditional advance(). We only consume the current character if it's what we are looking for.
Using match(), we recognize these lexemes in two stages. When we reach, for example, !, we jump to its switch case. That means we know the lexeme starts with !. Then we look at the next character to determine if we’re on a != or merely a !.
#7 Longer Lexemes
We are still missing one operator: / for division. That character needs a little special handling because comments begin with a slash too.
case '/':
if (match('/')) {
// A comment goes until the end of the line.
while (peek() != '\n' && !isAtEnd()) advance();
} else {
addToken(SLASH);
}
break;This is similar to the other two-character operators, except that when we find a second /, we don’t end the token yet. Instead, we keep consuming characters until we reach the end of the line.
This is our general strategy for handling longer lexemes. After we detect the beginning of one, we shunt over to some lexeme-specific code that keeps eating characters until it sees the end.
We have got another helper:
char Scanner::peek() const {
if (isAtEnd()) return '\0';
return source[current];
}
It’s sort of like advance(), but doesn’t consume the character. This is called lookahead. Since it only looks at the current unconsumed character, we have one character of lookahead. The smaller this number is, generally, the faster the scanner runs. The rules of the lexical grammar dictate how much lookahead we need. Fortunately, most languages in wide use peek only one or two characters ahead.
Comments are lexemes, but they aren’t meaningful, and the parser doesn’t want to deal with them. So when we reach the end of the comment, we don’t call addToken(). When we loop back around to start the next lexeme, start gets reset and the comment’s lexeme disappears in a puff of smoke.
While we’re at it, now’s a good time to skip over those other meaningless characters: newlines and whitespace.
case ' ':
case '\r':
case '\t':
// Ignore whitespace.
break;
case '\n':
line++;
break;When encountering whitespace, we simply go back to the beginning of the scan loop. That starts a new lexeme after the whitespace character. For newlines, we do the same thing, but we also increment the line counter. (This is why we used peek() to find the newline ending a comment instead of match(). We want that newline to get us here so we can update line.)
Our scanner is getting smarter. It can handle fairly free-form code like:
// this is a comment
(( )){} // grouping stuff
!*+-/=<> <= == // operators# String literals
Now that we’re comfortable with longer lexemes, we’re ready to tackle literals. We’ll do strings first, since they always begin with a specific character, ".
case '"': string(); break;That calls:
void Scanner::string() {
while (peek() != '"' && !isAtEnd()) {
if (peek() == '\n') line++;
advance();
}
if (isAtEnd()) {
// Unterminated string error
return;
}
// Consume the closing ".
advance();
// Extract the string value and add the token
std::string value = source.substr(start + 1, current - start - 2); // Exclude quotes
addToken(TokenType::STRING, new std::string(value));
}
Like with comments, we consume characters until we hit the " that ends the string. We also gracefully handle running out of input before the string is closed and report an error for that.
For no particular reason, FarmScript supports multi-line strings. There are pros and cons to that, but prohibiting them was a little more complex than allowing them, so I left them in. That does mean we also need to update line when we hit a newline inside a string.
Finally, the last interesting bit is that when we create the token, we also produce the actual string value that will be used later by the interpreter. Here, that conversion only requires a substring() to strip off the surrounding quotes. If FarmScript supported escape sequences like \n, we’d unescape those here.
# Number literals
All numbers in FarmScript are floating point at runtime, but both integer and decimal literals are supported. A number literal is a series of digits optionally followed by a . and one or more trailing digits.
To recognize the beginning of a number lexeme, we look for any digit. It’s kind of tedious to add cases for every decimal digit, so we’ll stuff it in the default case instead.
default:
if (isDigit(c)) {
number();
} else {
Lox.error(line, "Unexpected character.");
}
break;This relies on this little utility:
bool Scanner::isDigit(char c) const {
return c >= '0' && c <= '9';
}
Once we know we are in a number, we branch to a separate method to consume the rest of the literal, like we do with strings.
void Scanner::number() {
while (isDigit(peek())) advance();
// Look for a fractional part.
if (peek() == '.' && isDigit(peekNext())) {
// Consume the "."
advance();
while (isDigit(peek())) advance();
}
// Parse the number string and add the token
std::string numberStr = source.substr(start, current - start);
double value = std::stod(numberStr);
addToken(TokenType::NUMBER, &value);
}
We consume as many digits as we find for the integer part of the literal. Then we look for a fractional part, which is a decimal point (.) followed by at least one digit. If we do have a fractional part, again, we consume as many digits as we can find.
Looking past the decimal point requires a second character of lookahead since we don’t want to consume the . until we’re sure there is a digit after it. So we add:
char Scanner::peekNext() const {
if (current + 1 >= source.length()) return '\0';
return source[current + 1];
}
# Complete Code #
#include <iostream>
#include <unordered_map>
#include <string>
#include <vector>
enum class TokenType {
// Single-character tokens
LEFT_PAREN, RIGHT_PAREN, LEFT_BRACE, RIGHT_BRACE,
COMMA, DOT, MINUS, PLUS, SEMICOLON, SLASH, STAR,
// One or two character tokens
BANG, BANG_EQUAL,
EQUAL, EQUAL_EQUAL,
GREATER, GREATER_EQUAL,
LESS, LESS_EQUAL,
// Literals
IDENTIFIER, STRING, NUMBER,
// Keywords
AND, CLASS, ELSE, FALSE, FUN, FOR, IF, NIL, OR,
PRINT, RETURN, SUPER, THIS, TRUE, VAR, WHILE,
// End of file
EOF_TOKEN
};
class Token {
public:
TokenType type;
std::string lexeme;
int line;
Token(TokenType type, std::string lexeme, int line)
: type(type), lexeme(lexeme), line(line) {}
};
class Scanner {
private:
const std::string source;
std::vector<Token> tokens;
int start = 0;
int current = 0;
int line = 1;
static const std::unordered_map<std::string, TokenType> keywords;
char advance() {
return source[current++];
}
bool isAtEnd() const {
return current >= source.length();
}
void addToken(TokenType type) {
tokens.push_back(Token(type, source.substr(start, current - start), line));
}
bool match(char expected) {
if (isAtEnd()) return false;
if (source[current] != expected) return false;
current++;
return true;
}
char peek() const {
if (isAtEnd()) return '\0';
return source[current];
}
char peekNext() const {
if (current + 1 >= source.length()) return '\0';
return source[current + 1];
}
void string() {
while (peek() != '"' && !isAtEnd()) {
if (peek() == '\n') line++;
advance();
}
if (isAtEnd()) {
std::cerr << "Unterminated string." << std::endl;
return;
}
advance(); // Consume the closing '"'
std::string value = source.substr(start + 1, current - start - 2);
addToken(TokenType::STRING);
}
void number() {
while (isDigit(peek())) advance();
if (peek() == '.' && isDigit(peekNext())) {
advance();
while (isDigit(peek())) advance();
}
addToken(TokenType::NUMBER);
}
bool isDigit(char c) const {
return c >= '0' && c <= '9';
}
bool isAlpha(char c) const {
return (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || c == '_';
}
bool isAlphaNumeric(char c) const {
return isAlpha(c) || isDigit(c);
}
void identifier() {
while (isAlphaNumeric(peek())) advance();
std::string text = source.substr(start, current - start);
auto it = keywords.find(text);
TokenType type = (it != keywords.end()) ? it->second : TokenType::IDENTIFIER;
addToken(type);
}
public:
Scanner(std::string source) : source(source) {}
std::vector<Token> scanTokens() {
while (!isAtEnd()) {
start = current;
scanToken();
}
tokens.push_back(Token(TokenType::EOF_TOKEN, "", line));
return tokens;
}
void scanToken() {
char c = advance();
switch (c) {
case '(': addToken(TokenType::LEFT_PAREN); break;
case ')': addToken(TokenType::RIGHT_PAREN); break;
case '{': addToken(TokenType::LEFT_BRACE); break;
case '}': addToken(TokenType::RIGHT_BRACE); break;
case ',': addToken(TokenType::COMMA); break;
case '.': addToken(TokenType::DOT); break;
case '-': addToken(TokenType::MINUS); break;
case '+': addToken(TokenType::PLUS); break;
case ';': addToken(TokenType::SEMICOLON); break;
case '*': addToken(TokenType::STAR); break;
case '!': addToken(match('=') ? TokenType::BANG_EQUAL : TokenType::BANG); break;
case '=': addToken(match('=') ? TokenType::EQUAL_EQUAL : TokenType::EQUAL); break;
case '<': addToken(match('=') ? TokenType::LESS_EQUAL : TokenType::LESS); break;
case '>': addToken(match('=') ? TokenType::GREATER_EQUAL : TokenType::GREATER); break;
case '/':
if (match('/')) {
// A comment goes until the end of the line.
while (peek() != '\n' && !isAtEnd()) advance();
} else {
addToken(TokenType::SLASH);
}
break;
case ' ':
case '\r':
case '\t':
// Ignore whitespace.
break;
case '\n':
line++;
break;
case '"': string(); break;
default:
if (isDigit(c)) {
number();
} else if (isAlpha(c)) {
identifier();
} else {
std::cerr << "Unexpected character." << std::endl;
}
break;
}
}
};
const std::unordered_map<std::string, TokenType> Scanner::keywords = {
{"and", TokenType::AND},
{"class", TokenType::CLASS},
{"else", TokenType::ELSE},
{"false", TokenType::FALSE},
{"for", TokenType::FOR},
{"fun", TokenType::FUN},
{"if", TokenType::IF},
{"nil", TokenType::NIL},
{"or", TokenType::OR},
{"print", TokenType::PRINT},
{"return", TokenType::RETURN},
{"super", TokenType::SUPER},
{"this", TokenType::THIS},
{"true", TokenType::TRUE},
{"var", TokenType::VAR},
{"while", TokenType::WHILE}
};
int main() {
std::string source = "var x = 3.14;";
Scanner scanner(source);
std::vector<Token> tokens = scanner.scanTokens();
for (const auto& token : tokens) {
std::cout << "Type: " << static_cast<int>(token.type)
<< ", Lexeme: " << token.lexeme
<< ", Line: " << token.line << std::endl;
}
return 0;
}Output:
Type: 36, Lexeme: var, Line: 1
Type: 19, Lexeme: x, Line: 1
Type: 13, Lexeme: =, Line: 1
Type: 21, Lexeme: 3.14, Line: 1
Type: 8, Lexeme: ;, Line: 1
Type: 38, Lexeme: , Line: 1

Leave a comment
Your email address will not be published. Required fields are marked *