Tries, also known as prefix trees, are specialized data structures used primarily for storing and searching strings efficiently. They are especially useful for scenarios involving prefixes or substring searches, such as autocomplete systems, dictionary implementations, or spell checkers.
Each node in a Trie represents a single character of a word, allowing for efficient addition, retrieval, and deletion of words.
In simpler terms, a Trie is an advanced information retrieval data structure. It outperforms more conventional data structures like Hashmaps and Trees in terms of the time complexity for various operations, making it particularly useful for tasks involving large sets of strings or words.
The Trie data structure is designed to store and quickly retrieve a collection of strings.
It arranges strings so that shared prefixes are stored once, which makes it very efficient for operations like searching for words with a specific prefix. This ability to quickly find all strings that start with a given prefix makes Tries particularly useful for applications like autocomplete and predictive text. Trie Node Structure
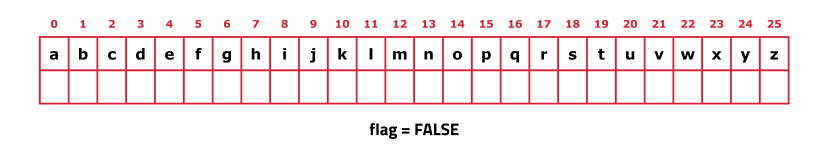
A Trie node is a fundamental element used to build a Trie. Each node consists of the following parts:
- Child Node Links: A Trie node has an array of pointers, often referred to as "links" or "children pointers," for every letter of the lowercase alphabet. These pointers create connections to child nodes that represent each letter of the alphabet. For example, the link at index 0 corresponds to the child node for the letter 'a', the link at index 1 corresponds to 'b', and so on.
- End-of-Word Flag: Each Trie node includes a boolean flag that signifies whether the node marks the end of a word. This flag is crucial for differentiating between prefixes and full words stored in the Trie.
Each node in the Trie supports several key operations:
- Contains Key: This operation checks if a specific letter (or key) exists as a child node of the current Trie node. It returns true if the letter is present, indicating a valid path in the Trie.
- Get Child Node: Given a letter, this operation retrieves the corresponding child node from the current Trie node. If the letter is present, it returns a pointer to the child node; otherwise, it returns null, indicating the letter is absent.
- Put Child Node: This operation creates a link between the current Trie node and a child node representing a specific letter. It sets the link at the corresponding index to point to the given child node.
- Set End Flag: This operation marks the current Trie node as the end of a word. This flag is essential for determining if a string stored in the Trie ends at this node, indicating a complete word.
- Is End of Word: This operation checks if the current Trie node marks the end of a word by examining the end flag. It returns true if the node signifies the end of a word; otherwise, it returns false.
Properties of Tries
1. Hierarchical Structure
- Tries are tree-like structures where:
- Each level represents a character in a string.
- Each path from the root to a node corresponds to a prefix of one or more stored strings.
2 Prefix Sharing
- Common prefixes are stored only once, leading to space optimization for datasets with overlapping prefixes.
Example: For the words cat, car, and care:
c
/ \
a r
/ \
t r
e
3. Dynamic Node Size
- Each node contains:
- Children pointers: Links to child nodes corresponding to the possible next characters.
- End-of-word flag: Marks whether the current node completes a word.
- The size of the children array depends on the character set (e.g., 26 for lowercase English letters).
4. Case Sensitivity
- By default, tries are case-sensitive. To make them case-insensitive, you can normalize input strings (e.g., convert to lowercase).
5. Efficient Operations
- Insert: Inserting a string takes O(m), where m is the string length.
- Search: Searching for a string or prefix also takes O(m).
- Delete: Deleting a string requires traversing and removing nodes that no longer serve other strings.
6. Space Usage
- Space usage depends on:
- Total number of characters in all stored strings.
- The size of the alphabet (e.g., English letters, Unicode characters).
- Drawback: Tries can consume significant memory for sparse datasets or large alphabets.
7. Supports Various String Operations
- Tries enable efficient execution of:
- Prefix queries: Quickly find all strings starting with a given prefix.
- Autocomplete: Retrieve all words matching a given prefix.
- Pattern matching: Match strings with wildcards or specific patterns.
- Lexicographical sorting: The trie structure inherently orders strings lexicographically.
Approach
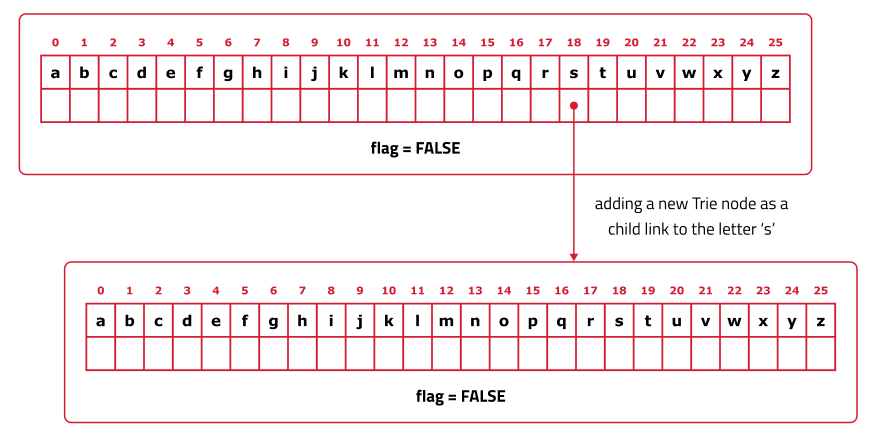
To insert a Node in the Trie:
- Being at the root node.
- For each character in the word:
- Check if the current node has a child node for the character.
- If the child node doesn't exist, create a new node and link it to the current node.
- Move to the child node that corresponds to the character.
- After inserting all characters, mark the end of the word by setting the end flag of the last node to true.
