
SQL Injection Explained
Learn how SQL Injection works with real examples and a hands-on demo using PHP and MySQL. Explore a GitHub repo with vulnerable code to safely test and understand this critical web vulnerability.

Master the art of analyzing constraints in DSA problems to choose optimal solutions, prevent TLE, and understand how online judges evaluate submissions.
When solving problems in Data Structures and Algorithms (DSA), constraints serve as a guide to select the most efficient approach. Constraints—provided in the problem description—tell us how large the inputs can be, how fast the algorithm must run, and what kind of data structures or optimizations we might need. Understanding and interpreting these constraints is a valuable skill for any developer.
Table of contents [Show]
In DSA problems, constraints are rules or limits defined for the input and output. They help us:
This tells you how large the input can be, which directly affects the type of algorithm you should consider. A brute-force approach that works for small input sizes may not be feasible for larger ones. It often appears something like n <= 10^5, where n is the number of elements in the input.
1 ≤ n ≤ 10^5: The input size (n) can be up to 100,000 elements.1 ≤ T ≤ 100: There can be up to 100 test cases.1 ≤ rows, cols ≤ 1000: For matrix problems, this defines the grid dimensions.💡 Input size directly impacts the algorithm you choose. For example:
- O(n²) is okay if n ≈ 1000
- O(n log n) is safe if n ≤ 10^5
- O(n) is ideal when n approaches 10^8
These define the possible range of values for each element. For example, a problem might specify that all numbers are between 1 and 1000. This can affect whether you should use certain data structures, like hash maps or arrays, for efficient lookup or computation.
1 ≤ arr[i] ≤ 10^6: Each array element is between 1 and 1,000,000.-10^9 ≤ x ≤ 10^9: Common in problems involving coordinates or ranges.These affect:
long long in C++ or int64)These describe:
For example: “Output should be accurate up to 6 decimal places” or “Return -1 if not possible.”
Because it tells you how much work your code needs to do in the worst case and what kind of algorithms will run within time limits.
When you submit code to platforms like LeetCode, Codeforces, or HackerRank, your solution goes through a multi-step process to evaluate its correctness and efficiency.
Online coding platforms uses a systematic process to evaluate submissions and determine if they pass the test cases.
Each problem has a set of input and expected output files stored behind the hood.
I1, I2, I3, ...In = Input files
EO1, EO2, EO3, ...EOn = Output files with expected outputWhen we submit the code, it is run against all these input files. This generates a list of generated output file.
GO1, GO2, GO3, ...GOn = Generated OutputThe generated output files are compared with the corresponding expected output files. If they match, your solution is correct.
Here's a detailed look at how this process works from submission to result:
When you submit your solution on the platform, the code is uploaded to the platform's server and typically goes through a compilation phase (if the language requires compilation, such as C++ or Java).
During this phase:
To run the code securely and prevent it from affecting other users or the server, platforms often execute code in isolated environments or sandboxes.
Each submission runs in the container or virtual machine with:
The isolation ensures that even if the code contains infinite loops, malicious instructions, or excessive memory usage, it won't impact the platform's stability.
Once the code is running in the sandbox, the platform runs it against a series of test cases:
Each test case is typically provided to the program through standard input and evaluate based on the standard output.
Each problem has a set of:
When your code runs:
During execution, the platform monitors CPU time and memory usage for each test case:
These limits ensures that inefficient or resource-intensive solutions fail, encouraging uses to optimize their code.
For each test case, the platform compares the program's output to the expected output:
If the output matches the expected result for a test case, that test case is marked as passed. Otherwise, it fails with an Incorrect Answer (WA) error.
After running all test cases, the platform compiles the result:
Accepted.Some platforms show partial results if only a subset of test cases pass, along with the score associated with those cases.
| Step | Description |
|---|---|
| 1. Submission & Compilation | Checks for syntax errors |
| 2. Isolation | Runs in a sandboxed environment |
| 3. Test Execution | Feeds inputs and captures outputs |
| 4. Limits Enforced | Applies time/memory constraints |
| 5. Output Validation | Matches actual output with expected |
| 6. Edge/Stress Tests | Ensures robustness |
| 7. Feedback | Shows pass/fail status per test case |
| 8. Scoring | Awards points and ranks submissions |
n to go up to 10^5, the developer should be able to recognize that a brute-force won't work and instead apply a more efficient algorithm.n >= 1, it suggests that the code should handle small input gracefully, such as an array with a single element.O(1) lookups rather than a list that requires O(n) searches.Overall, constraints push developers to consider the problem’s complexity and improve their problem-solving skills by choosing the right tools and methods.
Most coding platforms assume that their server can handle about 10^8 operations per second. This estimation helps set a practical standard for time limits on problems and serves as a benchmark for developers to gauge the efficiency of their solutions.
10^8 operations per second, this allows around 10^8 to 2*10^8 operations in the allotted time.10^8 operations per second benchmark provides a consistent guideline that works well across platforms, allowing developers to make reasonable assumption about time limits when planning their solutions.While the actual computation power may be higher, the 10^8 operations per second estimate is a useful benchmark.
O(n^2) works only if n ~ 10^3O(n log n) works if n ~ 10^5 to 10^6O(n) works for n ~ 10^7 to 10^8These constraints specify the size of the input data, such as the number of elements in an array, the length of a string, or the number of test cases.
n ≤ 10^5 means that the array or list can contain up to 100,000 elements.T ≤ 100, indicating that up to 100 test cases may be provided.1 ≤ rows, columns ≤ 1000 specify the maximum possible matrix size.| Constraint | Meaning |
|---|---|
n ≤ 10^5 | Max 100,000 elements |
T ≤ 100 | Up to 100 test cases |
1 ≤ rows, cols ≤ 1000 | Matrix dimensions |
These constraints indicate the range of values that elements can take within the input structures (like arrays, matrices, or strings).
1 ≤ arr[i] ≤ 10^6, which define the minimum and maximum values that each element in an array can hold.1 ≤ |S| ≤ 10^5 specify the maximum string length, and if the problem mentions that S contains only lowercase letters, you don’t have to handle uppercase letters or other characters.0 ≤ x ≤ 10^9 indicate the allowed range of values for a number. If values can be negative, this will also be mentioned, such as -10^6 ≤ x ≤ 10^6.| Constraint | Meaning |
|---|---|
1 ≤ arr[i] ≤ 10^6 | Element values between 1 and 1,000,000 |
| ` | S |
-10^6 ≤ x ≤ 10^6 | Handle negative numbers |
Output constraints specify requirements for the solution's format or precision.
|answer - expected_answer| < 10^-6 to indicate acceptable precision tolerance.output % 10^9 + 7).| Type | Example |
|---|---|
| Precision | ` |
| Format | Output "YES"/"NO" exactly as asked |
| Modulo | Output result as ans % (10^9 + 7) |
Some problems come with additional constraints or conditions that influence your approach.
1 ≤ L, R ≤ n). This can indicate whether solutions should involve preprocessing or advanced data structures like segment trees or binary indexed trees for efficient query handling.| Type | Example |
|---|---|
| Sorted Input | Enables binary search |
| Unique Elements | No need to check for duplicates |
| Tree/Graph Properties | Connected, undirected, acyclic, etc. |
Edge case constraints help clarify unusual scenarios that should be handled.
1 ≤ n ≤ 1000 imply that n could be as low as 1, meaning your solution should handle single-element cases gracefully.x = 10^9, be prepared to manage potential integer overflow, or consider more efficient approaches if necessary.When solving DSA problems, constraints often hint at the expected time complexity rather than stating it outright. You need to deduce whether your algorithm can run within the time limit, typically 1 second per test case, based on input size.
Here's a quick cheat sheet to guide your thinking:
Constraint on n | Acceptable Time Complexity |
|---|---|
n ≤ 10 | O(n!), O(2^n) (brute-force OK) |
n ≤ 100 | O(n^3) |
n ≤ 1,000 | O(n^2) |
n ≤ 10^5 | O(n log n) or better |
n ≤ 10^6 – 10^7 | O(n) only |
n ≥ 10^8 | Constant time operations only |
Below is given the all possible complexities on a graph:
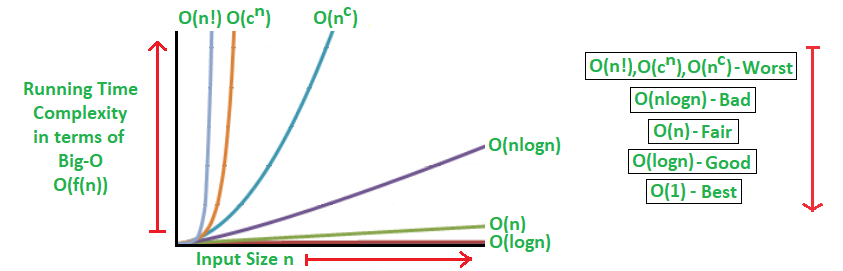
Use the 10^8 operations per second rule:
n constraint from the problem.n, n log n, n^2, etc.). By replace the n with your value.If the number of operations is within 10^8, your code is likely to complete within 1 second and pass the time limit. If it's significantly over 10^8, your code may result in a Time Limit Exceeded (TLE) error, especially if the platform has a strict 1-second limit per test case.
Let's say we have a problem with a constraint: n ≤ 10^5, and your solution has a time complexity of O(n^2).
Calculate Operations:
n^2 = (10^5)^2 = 10^10 operationsCompare to the 10^8 Benchmark:
10^10 operations > 10^8 operations ❌ Too SlowThis is far above 10^8, meaning your solution will likely exceed the time limit.
O(n^2) solution is too slow for n = 10^5 and may result in TLE. You would need to optimize the algorithm to something like O(n log n) or O(n) to make it feasible.Sometimes constraints on value ranges help you decide whether:
1 <= arr[i] <= 1000
This means you can safely use:
int freq[1001]; // For frequency counting
But if it was 1 <= arr[i] <= 1e9, then you would need a map instead of an array.
Always check the input size and pick the fastest possible algorithm. Use the below table to avoid TLE (Time Limit Exceeded) in interview or contests.
Max n | Time Complexity | Feasible Up To | Illustration | Common Algorithms |
|---|---|---|---|---|
10^18 | O(log n) | n ≤ 10^18 | log₂(10^18) ≈ 60 < 10^8 | Binary Search, Fast Exponentiation |
10^8 | O(n) | n ≤ 10^8 | 10^8 iterations | Linear Search, Prefix Sum |
10^6 | O(n log n) | n ≤ 10^6 | 10^6 × log₂(10^6) ≈ 10^6 × 20 = 2×10^7 | Sorting, Merge Sort, Heap, Divide & Conquer |
10^4 | O(n²) | n ≤ 10^4 | 10^4 × 10^4 = 10^8 | Brute Force, Dynamic Programming with 2 Loops |
500 | O(n³) | n ≤ 500 | 500³ = 1.25×10^8 | Matrix Multiplication, Floyd-Warshall |
100 | O(n⁴) | n ≤ 90 | 90⁴ ≈ 6.5×10^7 | High-dimensional DP |
25 | O(2^n) | n ≤ 25 | 2²⁵ ≈ 3.3×10^7 | Subset Enumeration, Bitmask DP, Recursion |
12 | O(n!) | n ≤ 10 to 12 | 12! ≈ 4.8×10^8 | Permutations, Backtracking |
O(log n) is super efficient. You can handle values up to 10^18 or more.O(n) is suitable up to n ≈ 10^8O(n log n) is efficient for n ≤ 10^6O(n²) is okay for n ≤ 10^4O(n³) starts becoming borderline at n ≈ 500O(n⁴) should only be used when n ≤ 90O(2^n) and O(n!) are only feasible for small n (usually n ≤ 25 or n ≤ 10 respectively)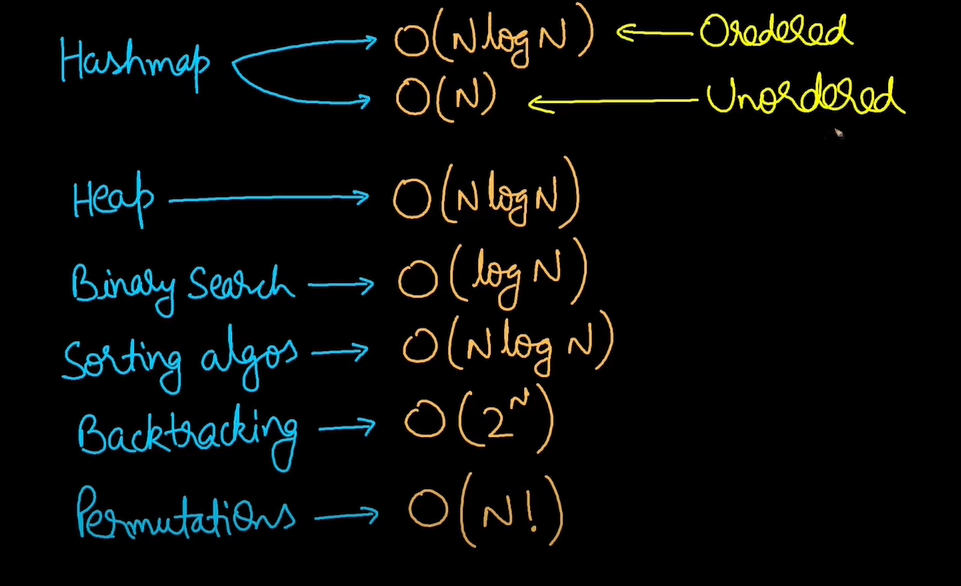


Your email address will not be published. Required fields are marked *





