
Overview
Here we will unravel the mystery behind how C++ code goes from plain text to a fully functioning program. Whether you are a novice programmer taking your first steps in C++ or a seasoned developer looking to deepen your knowledge, this one is tailored for you.
Our exploration will be divided into several stages, each shedding light on a crucial aspect of the compilation process. We will start by demystifying preprocessing, where code is prepared for compilation. From there, we will dive into the heart of compilation itself, where the code is transformed into object files.
But that's not all - we will also uncover the final piece of the puzzle: linking. This is where multiple object files come together to form the executable program you can run on your computer.
By the end of this journey, you will be armed with the knowledge to write more efficient, robust, and optimized C++ code. So, let's embark on this enlightening expedition into the compilation process of C++ programming.
Compilation Process
It is a series of steps that transforms human-readable source code, typically written in a high-level programming like C++, C, into machine-executable code that a computer can run. It ensures that code is translated, checked for errors, optimized, and prepared for execution.
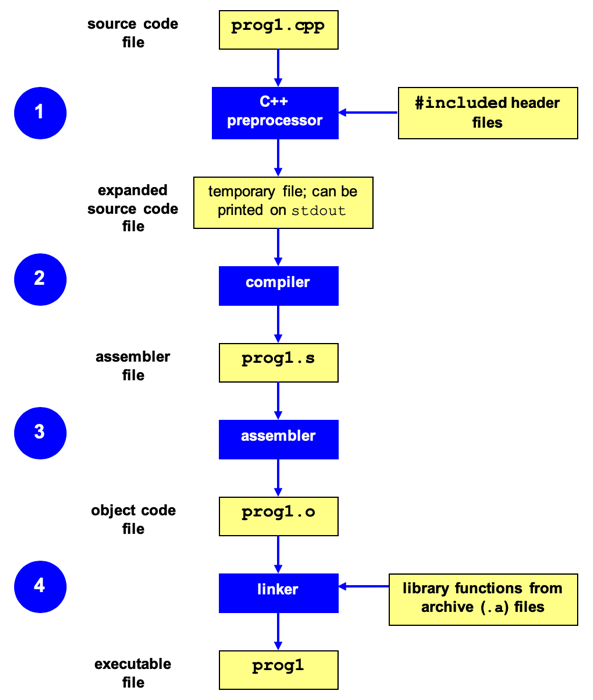
Here's an overview of the typical compilation process for C++ code:
1️⃣ Preprocessing (First Stage):
Preprocessing is the first stage of the compilation process in C++. Its primary purpose is to prepare the source code for actual compilation by the compiler. The output of the this step is called the preprocessed code. Preprocessing is done by a program called Preprocessor. The preprocessor performs several essential tasks, which are detailed below:
Inclusion of Header Files:
- The
#includedirective is used to include header files in the C++ code. - Header files contains declarations and definitions of functions, classes, and variables that your code relies on.
- The preprocessor copies the contents of the included header files into your source code, effectively replacing the
#includeline with the file's content.
e.g.,
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
During preprocessing, the content of the <iostream> header is copied into your source code.
Macros and Macros Expansion:
- Macros are defined using the
#definedirective. - They allow you to create symbolic constants or small code snippets that are replaced with their corresponding definitions during preprocessing.
- Macros are expanded by the preprocessor, and the result is substituted into your code.
e.g.,
#define SQUARE(x) (x * x)
int main() {
int result = SQUARE(5); // Expanded to: (5 * 5)
return 0;
}
The macro SQUARE(x) is expanded during preprocessing to (x * x).
Conditional Compilation:
- The preprocessor handles conditional compilation using
#ifdef,#ifndef,#else,#elif, and#endifdirectives. - These directives allow you to include or exclude portions of your code based on conditions, such as compiler flags or platform-specific requirements.
e.g.,
#ifdef _WIN32
// Windows-specific code
#endif
#ifndef _WIN32
// Non-Windows code
#endif
Depending on whether _WIN32 is defined, the corresponding code blocks are included or excluded during preprocessing.
Removal of Comments:
- Comments (both single-line and multi-line) are removed during preprocessing.
- This step helps reduce the size of the code that compiler needs to process, improve compilation efficiency.
e.g.,
int main() {
// This is a comment
int x = 5; // This is also a comment
return 0;
}
During preprocessing, all comments are stripped from the code.
Line Control:
- The preprocessor can insert line number and file information into the code using the
#linedirective. - This is useful for debugging, as error messages can reference the original source code lines.
e.g.,
#line 42 "myfile.cpp"
int main() {
// Error will reference line 42 in "myfile.cpp"
return 0;
}
The #line directive alters the line number and file information for error messages.
Symbolic Constants:
- You can define symbolic constants using
#define, making it easier to manage and update constant values throughout the code. - These constants are substituted wherever they are used in the code.
e.g., Defining a symbolic constant:
#define PI 3.14159265
double calculateArea(double radius) {
return PI * radius * radius;
}
Here, PI is defined as a symbolic constant, and it's substituted wherever used in the code.
Error Directives:
- The preprocessor can generate error messages or warnings using
#errorand#warningdirectives based on specific conditions. - This is often used for enforcing coding standards or highlighting potential issues.
e.g., Generating an error message with #error:
#ifndef DEBUG
#error DEBUG flag is not defined
#endif
If the DEBUG flag is not defined, a compilation error will occur with the specified message.
File Inclusion Guards:
- Header files commonly use include guards (e.g.,
#ifndef MY_HEADER_H,#define MY_HEADER_H,#endif) to prevent multiple inclusions and potential compilation errors.
e.g., File inclusion guards in a header file:
#ifndef MY_HEADER_H
#define MY_HEADER_H
// Header content
#endif
These guards ensure that the header file is included only once in a compilation unit, preventing multiple inclusions and potential errors.
2️⃣ Compilation (Second Stage):
Compilation Stage (Second Stage):
After preprocessing, the preprocessed code is passed to the actual compiler.
Compiler Responsibilities:
- The compiler is responsible for translating C++ code into low-level code.
- It performs syntax checking to ensure that the code adheres to the C++ language rules and generated the code that adheres to the target platform's architecture.
Generated Output:
The output of the compiler includes assembly code or an intermediate representation, such as LLVM IR in the case of LLVM-based compilers.
Nature of the Generated Code:
The generated code consists of low-level instructions but is not yet in the form of executable machine code.
3️⃣ Assembly/Code Generation Stage (Third Stage):
After the compiler generated assembly code or an intermediate representation, the assembly stage takes over. This stage is responsible for translating the intermediate code into actual machine code specific to the target hardware architecture.
In this stage of the compilation process, typically one object file is generated for each source file you compile. This means that if you have multiple source files (e.g., main.cpp, utils.cpp, math.cpp), each source file will be compiled into its own corresponding object file (e.g., main.o, utils.o, math.o). The purpose of creating object files for each source file is to maintain modularity and enable incremental compilation. Each object file contains the compiled code and data specific to its corresponding source file. Later, during the Linking stage, these individual object files are combined to create the final executable program.
Key Tasks in the Assembly/Code Generation Stage:
- Optimization: The assembly stage may include optimization steps where the generated code is analyzed and transformed to improve performance and efficiency. These optimizations can range from simple ones like constant folding to more complex optimizations like loop unrolling.
- Translation to Machine Code: The intermediate code, whether in the form of assembly language or another representation, is translated into machine code instructions that the CPU can understand. This involves converting high-level operations into low-level instructions specific to the processor architecture.
- Object File Generation: The result of this stage is typically an object file. Object file contain machine code, but they may also contain additional information needed for the linking stage, such as symbol tables and relocation information.
- Platform-Specific Considerations: The assembly stage takes into account the target platform's architecture and may generate different machine code for different CPU architecture or operating systems.
- Final Optimization: In some cases, additional optimization passes may occur at this stage, especially when using more advanced compilers or optimizing flags.
- Error Handling: The assembly stage may detect certain errors related to generation of machine code, such as addressing conflicts or unsupported instructions.
e.g., Suppose you have the following C++ program in a file named main.cpp:
#include <iostream>
int main() {
int x = 5;
int y = 7;
int sum = x + y;
std::cout << "The sum is: " << sum << std::endl;
return 0;
}
After preprocessing and compilation, you may have an intermediate representation or assembly code. For this example, let's consider a simplified assembly code representation:
section .data
sum_msg db "The sum is: ", 0
section .bss
x resb 4
y resb 4
sum resb 4
section .text
global main
main:
mov dword [x], 5
mov dword [y], 7
mov eax, [x]
add eax, [y]
mov [sum], eax
push sum_msg
call printf
add esp, 4
ret
Note: Keep in mind that real assembly code can be more complex, and modern compilers perform extensive optimizations. This example provides a simplified view to illustrate the transition from C++ code to assembly code during the Assembly/Code Generation stage of compilation.
4️⃣ Linking Stage (Fourth Stage):
After the compilation stage generates one or more object files (containing machine code and additional information), the linking stage takes place. The primary purpose of linking is to combine these object files into a single executable program, resolving references between them.
Key Tasks in the Linking Stage:
- Symbol Resolution: The linker resolves external references between object files. It ensures that functions and variables referenced in one file but defined in another are correctly connected.
- Library Inclusion: If your program uses functions or libraries from external sources (e.g., standard libraries), the linker includes the necessary library files.
- Relocation: The linker adjusts memory addresses in the machine code to match the final memory layout of the executable. This includes relocating address for variables and functions.
- Executable File Creation: The result of the linking stage is an executable file that contains all the necessary code and data to run your program. This file may also include additional information, such as program headers.
- Dynamic Linking (Optional): In some cases, the linker may perform dynamic linking, where certain library code is loaded at runtime rather than being included in the executable. This can reduce the size of the executable and allow for shared libraries.
- Error Handling: The linker checks for any unresolved external references or conflicts in the object files. It may report linker errors if it cannot resolve references.
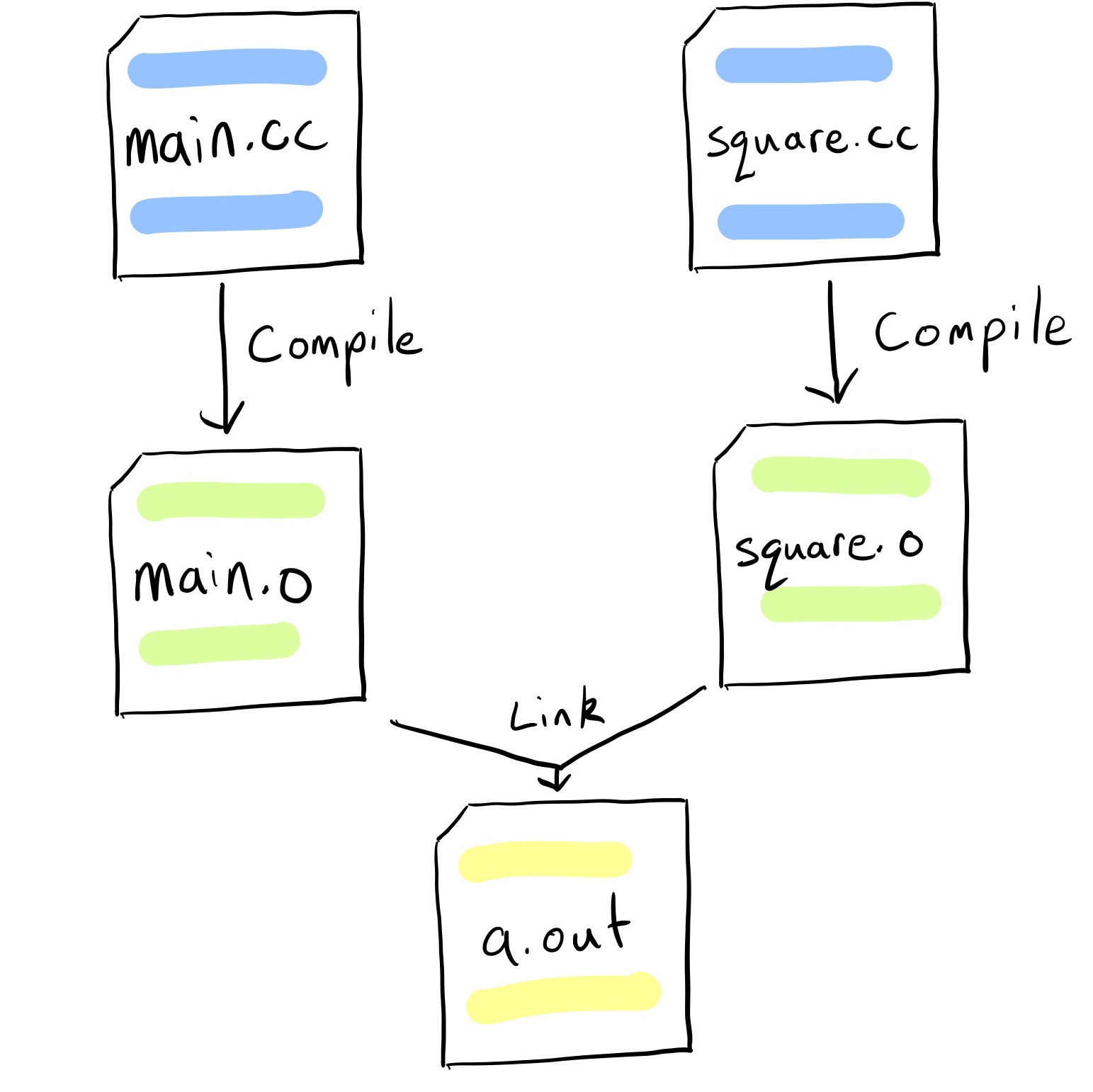
5️⃣ Loading and Execution Stage (Fifth Stage):
After the executable program is generated in the Linking stage, the responsibility for running the program shifts to the operating system or the runtime environment.
Key Tasks in the Loading and Execution Stage:
- Loading into Memory: The operating system or runtime environment loads the executable program from the storage medium (e.g., disk drive) into the computer's memory (RAM). The program's code and data are placed in memory locations allocated for its execution.
- Initialization: If necessary, the program's initialization code is executed. This code may set up variables, allocate additional resources, and perform other tasks required before the program starts executing its main logic.
- Execution: The program's entry point, often the
mainfunction in C++ programs, is invoked. Execution begins at this point, and the program follows the control flow specified in its code. - Interactions with the Operating System: The program may interact with the operating system for tasks such as file I/O, network communication, and memory management.
- Termination: When the program completes its execution or encounters an exit condition (e.g., reaching the end of the
mainfunction), it may return an exit status code. This code is often used to indicate whether the program executed successfully or encountered an error. - Memory Cleanup: The operating system releases the memory and system resources allocated to the program once it has finished executing.
- Error Handling: If the program encounters an error during execution, it may terminates with an error code. The operating system may also handle errors related to system resources or program execution.
The Loading and Execution stage is the final step in the compilation process and involves the actual running of the program on the computer. During this stage, the compiled and linked code becomes an executable process, and its behavior is determined by the instructions and logic within the program.
For example, after the Linking stage, when you run your C++ program with a command like ./main, the Loading and Execution stage begins. The OS loads the main executable into memory, starts executing it, and see the program's output or behavior on your computer.